Future of AI: Federated learning—the what and why for enterprises

Share this page

Ekin Karabulut
With the great improvements in research in machine learning (ML), many enterprises are deploying new ML techniques to improve their business processes. Unfolding the potential of ML gives them the adaptability to market changes quickly, understanding of the expectations of customers about their services and products, and the flexibility to scale those services and products. All of these results are possible with the data that we all own, from blood test results, MRI scans, and bank account transactions to Instagram and Twitter likes, and the comments that you write about your friends’ posts and tweets. In today’s world, data is the new oil, and that introduces a very hot topic: data privacy. How can we enhance and even ensure data privacy while accessing the full potential of artificial intelligence?
How are the classical ML techniques used?
Traditionally, enterprises have been using model-centric ML approaches, which have the following structure: A central ML model, in the central server, is trained with all available training data. The focus is on finding the most suitable model architecture for the task. These models are very valuable to companies, which want to get the most out of their data.
With the recent data-centric AI trend, the focus of AI is shifting from model-centric to data-centric approaches. Data-centric AI focuses on systematically improving the available data, which yields faster model building, shorter time for deployment, and improved accuracy. However, this approach brings its own set of challenges regarding the accessibility of the data.
What is the challenge?
With humongous language models, like GPT-3 by OpenAI, we see that most models these days actually share the same architecture but are hard to train because they require a lot of computing and enormous amounts of data. With the utilization of GPUs on premises as well as on cloud platforms (SageMaker, Azure, etc.), it became easier to tackle the computation overhead. The new problem is getting access to those huge amounts of data without causing data breaches to the companies or to individuals.
Let’s assume that you want to deploy a model for your business, and you need data to train and validate your model. You need to gather as much data as possible from different regions to ensure generalization. You ask other companies, your customers, your partners, etc. for more data. But what if their training data reveals sensitive information about individuals, such as race, name, bank account details, and medical data, and therefore they don't want to share it, even with different branches of the same company or hospital?
Even if the sensitive information is removed or the dataset is revealed without the names of the individuals, attackers can still identify the individuals with just a small amount of information. An example of this situation is the “Netflix Prize.” In 2006, Netflix, the world’s largest online movie rental service, announced a challenge for their recommendation system, offering $1M to anyone who could improve their recommendation system by 10%. Netflix published a dataset with anonymous movie ratings of their 500,000 subscribers. Even though the dataset was anonymized, researchers proved that it was possible to identify a subscriber in the Netflix dataset just from knowing about a couple of the subscriber’s movie ratings on the Internet Movie Database (IMDB), which is open to everyone.
What is federated learning?
In response to rising concerns about data privacy, Google introduced a new approach called federated learning, which allows training models collaboratively without sharing raw local data. This method brings the model to the data rather than gathering the data in one place for the model training.
How does federated learning help?
The principle of federated learning is very simple. All clients that have data on them, such as smartphones, sensor data from cars, branches of a bank, and hospitals, train their individual models. They then send the model, not the data, to a central server that combines them and sends out the new combined model to every client for further updating rounds.
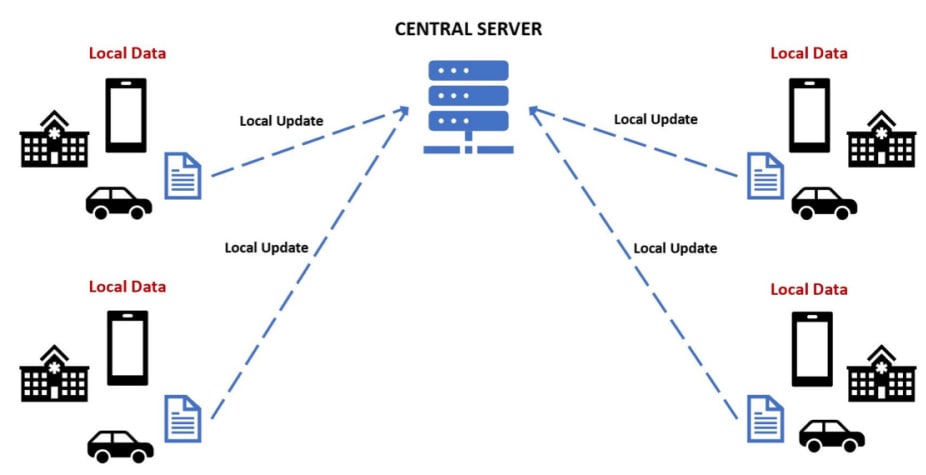
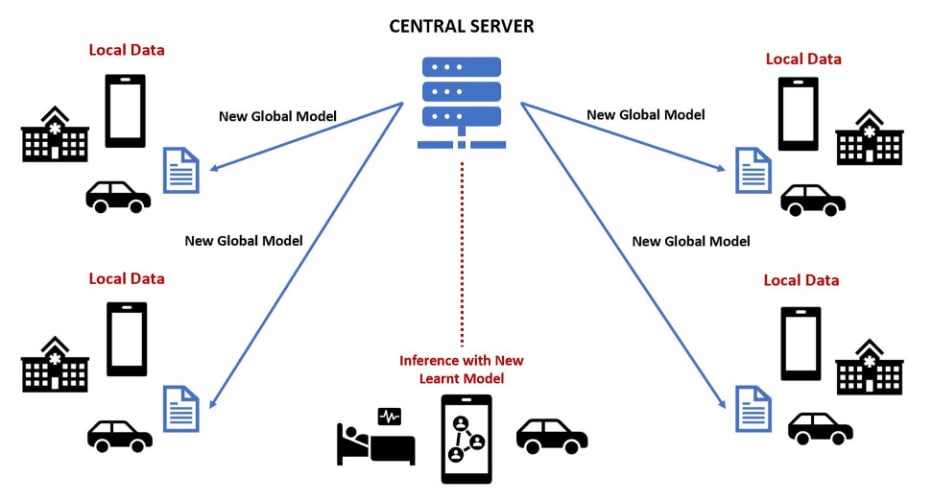
Detailed steps of federated learning
The central server holds a global model with initial parameters and the participants (also called clients or nodes) hold their local datasets without any intention of sharing them with third parties.
- The central server sends the initial model to every participant/client.
- The participants, who hold local data on premises or in the cloud, extract knowledge from their local data by training the model that the central server shared.
- The trained model is sent back to the central server for aggregation (Figure 1), which means that the server just takes the average of all models’ parameters.
- The central server shares the updated model with the participants (Figure 2).
In this way, all the clients have a say on the parameters of the updated model. This allows us to have a model trained with all of the data but without having the data itself. This loop is repeated until the model converges. The number of rounds varies depending on the data distribution, computation power, and communication efficiency of each client.
However, federated learning by itself is not enough to guarantee privacy. Therefore, the research describes many different techniques for enhancing privacy, such as federated learning with differential privacy, homomorphic encryption, and secure multiparty computation. This blog post doesn’t go into the details of these approaches but rather concentrates on federated learning, because the underlying idea is the same for all approaches, with modifications on top.
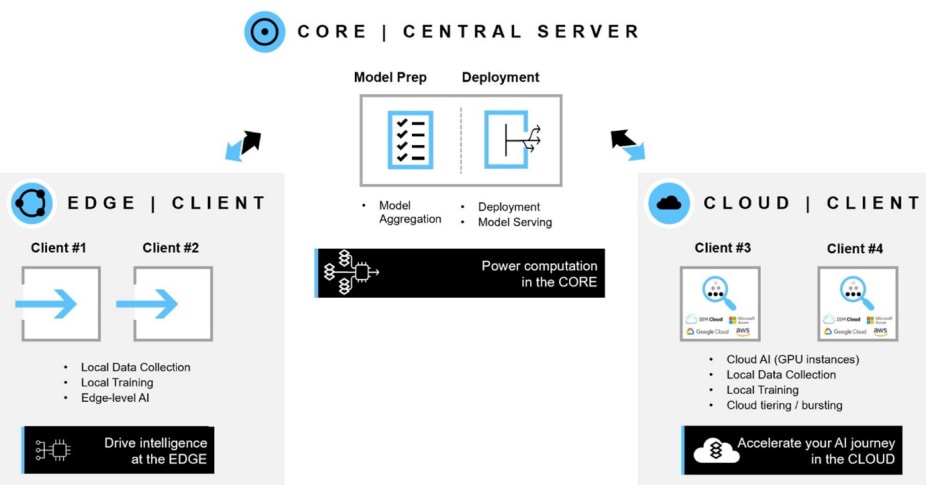
What does the technical setup look like? What does NetApp offer to relieve bottlenecks?
The location of datasets might vary from one client to another. Some enterprises prefer on-premises (core) resources, while others don’t want to go deep into an onsite solution and prefer to go for cloud solutions to accelerate their AI journey. When it comes to data mobility, NetApp® solutions play a huge role in the AI area. It doesn’t matter where the datasets of each local participant are, cloud, on premises, or edge. A data fabric powered by NetApp uses the data easier and faster, wherever and whenever it’s needed and closes the gap between different data locations. It also gives users increased flexibility in moving from one settings to another. Moving from cloud to edge or from on premises to cloud, the data fabric accelerates your journey without bothering you about the details. This flexibility is especially crucial in building an environment with a federated learning setting that needs to take care of different enterprises or individuals, which probably use different environments to store their data.
As with many ML-based projects, the data scientists who build the central model need to determine what kind of model is suitable for the specific use case. Experimentation leads to improved results in ML projects. Data scientists use different models with many combinations of configurations. Documenting this journey assures other data scientists in the project that all possible variables have been explored and that the results are reproducible. It’s crucial to create and share the versions with peers, either for cooperation or as proof. It’s also important for the company to retain the versions in case of a legal challenge, which can be caused by the predictions of a model after a deployment or update.
With the large number of update rounds and different model architectures, the versioning of the models and datasets via copies is time consuming and not scalable. Even if federated learning distributes the computation load of the datasets to different devices, there might be some participants with large datasets (e.g., 3D CT scans, MRI data of many patients, daily sensor data of autonomous cars), which need to be preserved and versioned on the client’s side. Also, it’s not difficult to imagine scenarios in which little accidents cause big problems, such as deleting the current model or experimenting with the new working version of the model without capturing the state of the model first. These mistakes cost a lot of time, because the data science team has to recreate each step, And they can cost corporations and research institutes a lot of money.
In addition to the data fabric, NetApp offers an open-source library, the NetApp DataOps Toolkit, which is the cherry on top for ML projects. Regardless of the dataset size, creating NetApp Snapshot™ copies of the model and dataset takes just a couple of seconds, rather than hours. Just clone the repository and import the function, and you’re ready to go. The data science team doesn’t have to bother with hours-long copying processes; they can simply add two lines to their project to take Snapshot copies and share them with colleagues or store them. Even in the worst-case scenario, the corruption or deletion of the current model, the data science team doesn’t have to start the project from the beginning. They can leverage the flexibility to manage the full state of the application stack. They can revert the application and data in case of corruption or accidental deletion and continue collaborating with the client side.
Federated learning is a special technique of AI with a lot of infrastructure and network requirements, which can turn into a large-scale hassle for data scientists in industry and research. NetApp’s offerings are a catalyst to accelerate the research and development steps with flexible scalability and high computational utility. NetApp is driven with the aim of empowering data scientists to add value to their work with state-of-the-art approaches without worrying about infrastructure details and infrastructural cost optimization.
For that purpose, we are always keeping this motto in mind: May the infrastructure be with NetApp, and may AI be with all data scientists!
For further reading:
Netflix Prize. K. Hafner. And if you liked the movie, a Netflix contest may reward you handsomely. New York Times, Oct 2, 2006.
De-anonymization of Netflix Dataset. A. Narayanan, V. Shmatikov. Robust De-anonymization of Large Datasets (How to Break Anonymity of the Netflix Prize Dataset). University of Texas at Austin, Feb 5, 2008.
Federated Learning. B. McMahan, D. Ramage. Federated Learning: Collaborative Machine Learning without Centralized Training Data. Google AI Blog, Apr 6, 2017.
Design of Federated Learning Systems. S. K. Loa, Q. Lua, L. Zhua, H. Y. Paik, X. Xua, C. Wanga. Architectural Patterns for the Design of Federated Learning Systems. Data61, CSIRO, Australia. June 18, 2021.
Ekin Karabulut
Next Steps
.png?width=5760&format=avif&disable=upscale)