What is federated learning in AI?

Share this page

Mike McNamara
As enterprises expand their artificial intelligence (AI) efforts, they must address important and sometimes difficult questions. Is AI being used responsibly? Can the results that AI produces be explained? Because data underpins all AI processes, this blog series looks at important AI questions from the standpoint of data, data management, and data governance. This final post in the series discusses federated learning.
According to Fortune Business Insights, the global Internet of Things (IoT) market is projected to grow from $385 billion in 2021 to $2,465 billion in 2029. Vast amounts of data are generated and stored on third-party devices, including a lot of personal data. Industries such financial services, retail, and healthcare want to take advantage of this data, but analysis raises significant data privacy issues, especially if you need to gather all the data in one place.
This blog post examines federated learning (FL), a training method that’s intended to help prevent sensitive data and personally identifiable information (PII) from being compromised. It explores different approaches and the data challenges that come with training at the edge.
What are the details about federated learning?
Typically, when you train a deep learning model—or any machine learning algorithm—you centralize all the training data in one place for better performance and ease of management. FL is a decentralized approach to model training. With FL, models are trained on third-party data by sending the model to the data instead of sending the data to the model. All the data is left in place, reducing data privacy concerns and network bandwidth requirements. When a model has been trained on a dataset, only the model—with updated weights and parameters—is returned. These values are then averaged with results from similar training runs that were performed elsewhere, reducing the risk of data traceability.
How does federated learning help AI?
FL enhances model training by reaching greater amounts of data in distributed locations and on edge devices, at the point of generation and consumption. This approach can provide a significant untapped reservoir of data that greatly expands the available dataset.
Is federated machine learning the same as distributed machine learning?
Federated machine learning is not to be confused with distributed machine learning. Distributed machine learning centralizes training data but distributes the training workload across multiple compute nodes. This method uses compute and memory more efficiently for faster model training. In federated machine learning, the data is never centralized. It remains distributed, and training takes place near or on the device where the data is stored.
What is a federated learning model?
FL is somewhat comparable to a crowdsourced Yelp rating that’s based on an average of hundreds of dining experiences. In an FL model, copies of the model to be trained are sent to many edge locations—possibly hundreds or thousands of them—to train on specific data. The model is trained locally without copying or sending data back.
For example, think of a familiar edge device like a cellphone. You could train a model—to improve speech to text, for example—by sending a small model to thousands of phones. The model is trained on the local data on each phone and is then returned to a central server, where all the results are compiled. The model is updated based on the compilation, and a new, smarter model is redeployed to repeat the process.
If this FL approach sounds theoretical to you, you should probably know that the concept originated at Google back in 2016. Google uses FL and offers FL tools. Apple has also been using FL for years to improve Siri.
How does federated learning work?
Fundamentally, FL requires just a few steps:
- An initial model is created.
- The model is selectively distributed to edge locations or to edge devices. If training is on edge devices like cellphones, care must be taken not to disrupt the user experience.
- The model is trained locally, by using local data, and the trained model is returned. All the data remains where it is; only weights, biases, and other parameters that the model has learned are returned.
- After trained models are returned, results are averaged and a new primary model is created and distributed.
A few variations on this approach can be employed for different use cases.
Centralized federated learning
Up to this point in the blog post, the descriptions cover centralized FL; a central server orchestrates the steps and coordinates the process. The server is responsible for model distribution at the beginning of the training process and for aggregation of the returned models. Because all updates are sent to a single entity, the server may become a bottleneck in this approach.
Decentralized federated learning
In decentralized FL, locations or individual devices coordinate among themselves to update the model. This method is valuable in cases such as training on streaming data, where every model iteration always trains on new data. Because model updates are exchanged only between interconnected nodes without requiring orchestration from a central server, this approach prevents a single point of failure. However, in decentralized FL, the network topology may affect the performance of the learning process.
Heterogeneous federated learning
The previous two strategies assume that devices have the same model architecture. However, an increasing number of use cases involve heterogeneous clients, like mobile phones and IoT devices. A new FL framework, heterogeneous FL, has been developed to use devices that are equipped with very different computation and communication capabilities. Different devices can train different subsets of model parameters, as illustrated in the following graphic from the original research paper.
Source: HeteroFL: Computation and Communication Efficient Federated Learning for Heterogeneous Clients.
Industry use cases for federated learning
FL can be particularly useful in situations where so much data is generated at the edge that data transfer to a central location would be prohibitive, such as data that’s generated by self-driving vehicles. It’s also useful in situations where data privacy is highly regulated, such as the healthcare industry.
Autonomous driving
FL seems like a natural fit for automobiles with advanced driver-assistance systems (ADAS), because data volumes are extremely high, network bandwidth is limited, and the cars have significant processing power already onboard. FL could be used to train a local model on each vehicle, by using the local dataset that vehicle operation generates. The local models can then be aggregated; each car’s model may also serve as a locally optimized model for that car, tailored to the region where it’s in use.
At this time, no active autonomous-driving program has officially announced the use of FL, so it remains a topic of research. Tesla Autopilot uses an alternative approach: It gathers only the “interesting” data from each car, where “interesting” data might include telemetry from around the time when a driver intervened. This approach significantly reduces the bandwidth that’s necessary to centralize data.
Healthcare
Health data is highly sensitive and tightly regulated. The application of AI to aid diagnosis in medical imaging requires large, curated datasets to achieve clinical-grade accuracy. But collecting, curating, and training on a high-quality dataset often require cross-silo FL, using image data from multiple institutions. With FL, model training can build a consensus model without moving patient data out of each institution. Successful implementation of FL enables precision medicine at scale, while respecting data governance and privacy concerns.
Another example of FL in healthcare was described in a recent NetApp blog (along with several financial services use cases). And as reported in Nature Medicine, the electronic medical record chest X-ray AI model (EXAM) study brought together 20 institutions to train a neural network to predict the future supplemental oxygen requirements of COVID-19 patients. NetApp has also collaborated with SFL Scientific to create a deep learning model for segmenting COVID-19 lung lesions.
What are the data challenges with federated learning?
Although FL presents an opportunity to reduce data risks, it also poses new risks that are not yet fully understood or resolved. Companies that implement FL must understand these threats and improve security around their FL models.
Recent research has demonstrated that retaining data and performing computation on-device by themselves are not sufficient to guarantee privacy. Model parameters exchanged between parties in an FL system may conceal sensitive information that can be exploited. FL on user devices, in particular, may be susceptible to data poisoning, in which training data is manipulated to alter or to corrupt the output of a trained model.
How can NetApp help?
Without rigorous data governance, data protection, and reliable AI infrastructure, FL is not likely to be effective. NetApp is therefore working to create advanced tools that eliminate bottlenecks and help AI engineers succeed. The combination of NetApp® AI Control Plane and the MLRun pipeline enables AI and machine learning model versioning, A/B testing, machine learning operations (MLOps), and serverless automation in Distributed Computing Environments. This combination also enables multinode AI and machine learning systems that run FL aggregate algorithms such as federated averaging (FedAvg) and SCAFFOLD.
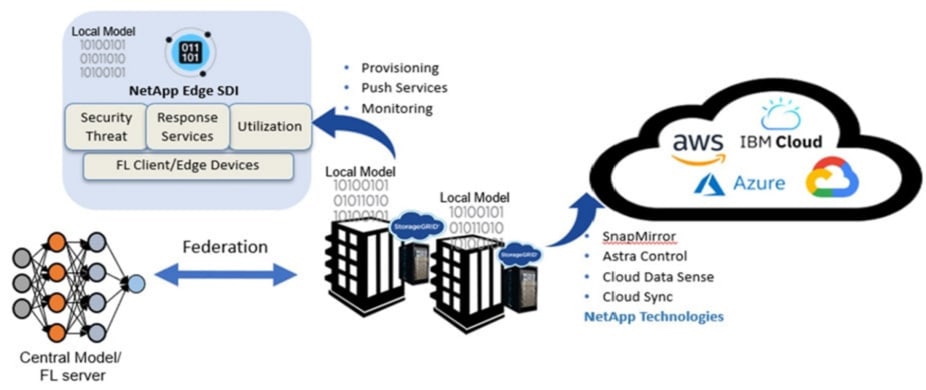
NetApp offers a wide variety of products and services with tools that enhance data privacy and compliance and that address a full range of cybersecurity threats. NetApp AI solutions give you the tools that you need to expand your AI efforts:
- NetApp ONTAP® AI accelerates all facets of AI training and inference.
- NVIDIA DGX Foundry with NetApp facilitates world-class AI development without the struggles that come with building everything yourself.
- NetApp AI Control Plane pairs MLOps and NetApp technology to simplify data management and to facilitate experimentation.
- NetApp DataOps Toolkit makes it easier to manage the large volumes of data that you need for AI.
- NetApp Cloud Data Sense helps you discover, map, and classify data. You can analyze a wide and growing range of data sources—structured and unstructured, in the cloud or on premises.
To find out how NetApp can help you deliver better data management and data governance for FL and all your AI projects, visit netapp.com/ai.
Mike McNamara
Mike McNamara is a senior product and solution marketing leader at NetApp with over 25 years of data management and cloud storage marketing experience. Before joining NetApp over ten years ago, Mike worked at Adaptec, Dell EMC, and HPE. Mike was a key team leader driving the launch of a first-party cloud storage offering and the industry’s first cloud-connected AI/ML solution (NetApp), unified scale-out and hybrid cloud storage system and software (NetApp), iSCSI and SAS storage system and software (Adaptec), and Fibre Channel storage system (EMC CLARiiON).
In addition to his past role as marketing chairperson for the Fibre Channel Industry Association, he is a member of the Ethernet Technology Summit Conference Advisory Board, a member of the Ethernet Alliance, a regular contributor to industry journals, and a frequent event speaker. Mike also published a book through FriesenPress titled "Scale-Out Storage - The Next Frontier in Enterprise Data Management" and was listed as a top 50 B2B product marketer to watch by Kapos.
Next Steps
.png?width=5760&format=avif&disable=upscale)