Enable instant data landing zones with ONTAP S3 NAS Volumes

Share this page

Win Vahlkamp
In today’s data-driven world, businesses demand faster, more efficient ways to manage and to analyze large volumes of unstructured data. Traditional extract, transform, load (ETL); extract, load, transform (ELT); and change data capture (CDC) pipelines introduce long wait times, making real-time data access and transformation challenging.
With NetApp® ONTAP® S3 NAS buckets, you can enable Simple Storage Service on any existing NFS or SMB volumes to create instant data landing zones. These landing zones simplify data ingestion and allow data catalogs to access the data. They also eliminate an entire class of ingestion pipelines, along with the engineering and infrastructure costs of those initial ingestion pipelines. This blog post explains how you can enable NAS buckets right now to take advantage of this game-changing capability.
What are landing zones?
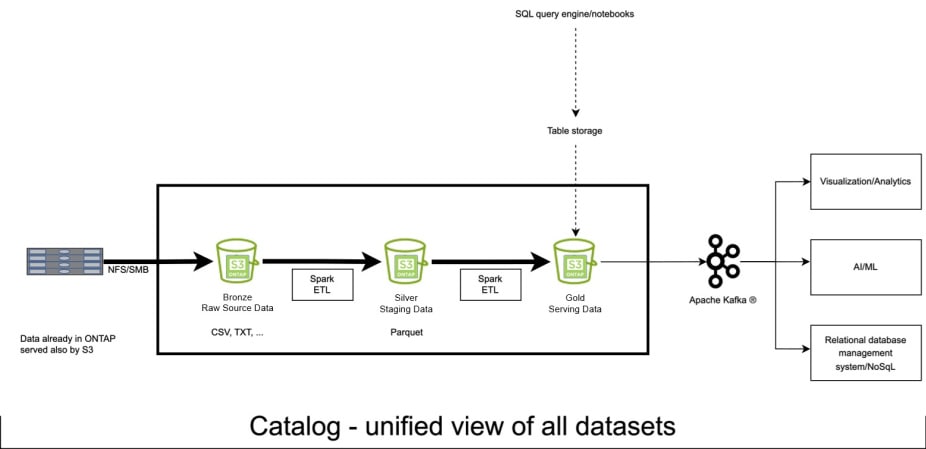
The medallion architecture of bronze (raw) > silver (staging) > gold (serving) is a common architectural pattern in data lake storage. Data is stored in its raw format in the bronze zone. It can be database exports to CSV files, log files, .txt files, or .jpg files, among many other data formats. Data is ingested by extracting the data from the source and loading it into the raw zone for later transformation (ELT). Data can be loaded into Hadoop® Distributed File System (HDFS) storage, Amazon S3 storage, Azure Data Lake Storage, or Google Cloud Storage. From there, in the silver zone the data is cleaned, aggregated, enriched, and transformed into a columnar data format, such as Apache Parquet™, according to the use case needs. Finally, datasets are created and stored in the gold zone.
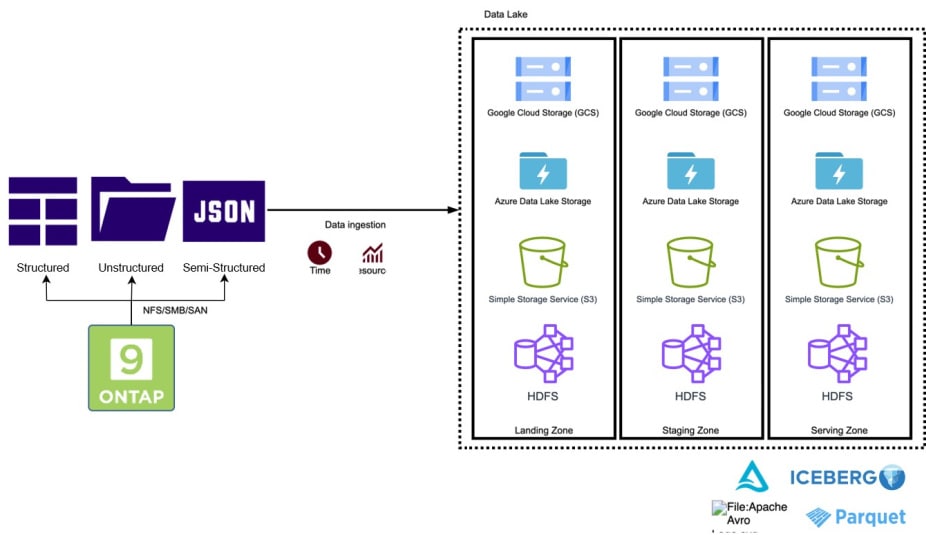
Building ELT pipelines to ingest into the raw bronze zone requires significant data engineering time and incurs costs for network infrastructure, bandwidth, and storage transactions. Wait times to get access to source data and to build extraction pipelines can be anywhere from 1 or 2 days to months.
Data engineers use catalogs to extract metadata for data exploration purposes; to open Python libraries such as Amazon Boto3, NumPy, and pandas for data exploration; and to use Apache Spark™ for extraction jobs. They also use many other tools for scheduling and for orchestration, such as Apache Airflow™. However, all these tools expect to use S3 to access the data. NetApp ONTAP supports the S3 protocol, which has become the de facto object storage standard protocol. What’s more, ONTAP also supports file duality on NAS (NFS/SMB) volumes to run multiple protocols, including S3.
By enabling S3 on your existing NAS volumes, you make every volume an instant landing zone—without all the time, tooling, and effort required to build those ingestion pipelines. You then reduce your wait time to zero to begin the next stage of the data journey, instead of having to wait a month or more.
Conceptually, configuring this multiprotocol configuration with NFS or SMB and S3 makes a “front-end” protocol of NFS or SMB and a “back-end” protocol of S3. All the data that’s stored in NAS volumes is then available to all the data engineering and data science tools that are in use today. The data is fully deduplicated, compressed, and compacted already by virtue of being stored in ONTAP. And these volumes are already being backed up, so there’s no additional effort required for you to back up or to replicate the data. The data is also already encrypted on disk, so you incur no additional costs in encryption. Plus, the AI-driven anti-ransomware capabilities of ONTAP along with NetApp Snapshot™ technology protect your data from attacks, with no extra tooling or administration time required.
How to build an instant data landing zone
It’s easy to enable instant landing zones and to process data. Follow these steps:
- In ONTAP System Manager, Storage > Storage VMs, select a storage VM, click Settings, click the gear under S3, then click Enable S3
- Click Storage > Buckets, then click Add.
a. Name the bucket, browse to the NAS volume and select it.
b. Add any other settings that are particular to your use case. - Click Save to create the bucket.
Now you can assign bucket policies and create S3 users for access to that new bucket. Most likely, you already have your ONTAP cluster joined to an Active Directory domain. If so, grant your Active Directory users access to the S3 bucket with the Lightweight Directory Access Protocol (LDAP).
You have just created an instant landing zone in a matter of minutes, and that data is now accessible to your data catalog for classification and exploration.
Simplify, enhance, and speed your unstructured data management today
By shifting from traditional ETL and ELT processes to an instant data landing zone model, you can:
- Eliminate long wait times in ingestion data pipelines.
- Eliminate the infrastructure costs incurred by the ingestion data pipelines.
- Make all your data that’s stored in ONTAP available for data catalogs and searches.
- Avoid the need to change the data source connections.
Get started today. Learn more about ONTAP S3 instant data landing zones and how they can help you drive innovation.
Win Vahlkamp
Win is a Data Solutions Architect with over 25+ years of experience in systems architecture and engineering. He is focused on developing open source data solutions across the NetApp’s cloud and on-prem portfolio of products and solutions. Previously, he was an Azure Cloud Solutions Architect, Global Technology Strategist, and Senior Solutions Engineer for some of the world’s largest oil companies. In his spare time, Win reads a lot, especially about Systems of Profound Knowledge (Deming) and the Theory of Constraints (Goldratt), practices Iaido (Japanese sword), and likes to travel.