AWS High Availability Zones mit Cloud Volumes ONTAP
: Schritt für Schritt erklärt
Diese Seite teilen

Aviv Degani
AWS High Availability Best Practices mit Cloud Volumes ONTAP erklärt - Schritt für Schritt
Moderne Unternehmen betreiben Anwendungen mit sehr unterschiedlichen Anforderungen an Verfügbarkeit, Leistung und Wiederherstellungszeiten. Wie kritisch eine Anwendung eingestuft wird, hängt dabei maßgeblich von ihrer benötigten Performance, Antwortzeit und Ausfallsicherheit ab. Entsprechend hoch sind die Anforderungen an die zugrunde liegende Infrastruktur – insbesondere in Cloud-Umgebungen wie Amazon Web Services (AWS). AWS bietet mit Regionen, Availability Zones (AZs) und Placement Groups flexible Optionen zur Hochverfügbarkeits-Architektur. Durch die gezielte Kombination dieser AWS-Ressourcen mit einem hochverfügbaren Storage-Backend wie NetApp Cloud Volumes ONTAP lassen sich anspruchsvolle SLAs zuverlässig erfüllen.
In diesem Beitrag zeigen wir bewährte Methoden für hochverfügbare Deployments in AWS – sowohl innerhalb einzelner als auch über mehrere Availability Zones hinweg. Zudem erklären wir, wie Placement Groups optimal eingesetzt werden und welche zusätzlichen Vorteile Cloud Volumes ONTAP HA auf Storage-Ebene bieten.
Was sind AWS-Regionen und Availability Zones?
Innerhalb jeder Region betreibt AWS mehrere Availability Zones, also voneinander unabhängige Rechenzentren mit eigener Stromversorgung, Kühlung und Netzwerkverbindung. Diese AZs sind durch niedrig-latente, redundante Verbindungen untereinander verknüpft. Anwendungen können so verteilt bereitgestellt werden, dass sie bei einem Ausfall einzelner Infrastrukturkomponenten weiter funktionieren.
Wer seine Instanzen und Daten ausschließlich in einer einzigen Availability Zone hostet, läuft Gefahr, im Fall eines Ausfalls die gesamte Umgebung zu verlieren. Durch den Einsatz mehrerer AZs, auch bekannt als Multi-AZ-Deployment, lässt sich dieses Risiko signifikant reduzieren.
AWS bietet eine Übersicht aller weltweit verfügbaren Regionen und ihrer zugehörigen Availability Zones in der globalen Infrastrukturübersicht.
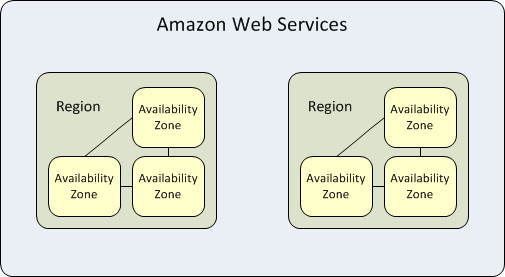
AWS Regionen vs. Availability Zones – die Unterschiede
Beim Design hochverfügbarer Cloud-Architekturen ist es entscheidend, die Unterschiede zwischen einer Verteilung über mehrere Availability Zones (AZs) innerhalb einer AWS-Region und der Nutzung mehrerer AWS-Regionen zu verstehen. Zwei zentrale Faktoren spielen dabei eine Rolle: geografische Verteilung und Kostenstruktur.
1. Geografische Verteilung und Ausfallsicherheit
Verteilung über Availability Zones in einer Region:
- Bietet Schutz vor Infrastrukturfehlern auf AZ-Ebene (z. B. Stromausfall, Hardware-Fehler).
- Hohe Verfügbarkeit durch redundante Bereitstellung in mehreren Rechenzentren derselben Region.
- Kein Schutz bei einem vollständigen Ausfall der Region (z. B. regionales Netzproblem, Naturkatastrophe).
Verteilung über mehrere Regionen:
- Höchstes Maß an Resilienz – selbst bei einem vollständigen Ausfall einer Region bleibt der Betrieb möglich.
- Bessere globale Abdeckung und geringere Latenz für weltweit verteilte Nutzer.
- Ermöglicht schnellere Disaster-Recovery-Szenarien durch regionale Redundanz.
Fazit:
Wer geschäftskritische Anwendungen mit strikten SLA-Anforderungen betreibt, sollte eine regionenübergreifende Redundanz in Erwägung ziehen. Für viele Standard-Workloads reicht jedoch ein Multi-AZ-Setup innerhalb einer Region aus.
2. Kosten für Compute und Datenübertragung
Regionale Preisunterschiede:
- AWS-Services unterscheiden sich preislich je nach Region. Gründe sind z. B. lokale Infrastrukturkosten, Steuerlast und Nachfrage.
- Beispiel: Ein EC2-Instance-Typ kann in der Region US East (N. Virginia) deutlich günstiger sein als in Asia Pacific (Mumbai).
| Übertragungsart | Kostenfaktor |
| Innerhalb einer Availability Zone | Meist kostenlos |
| Zwischen AZs in derselben Region | Geringe Kosten |
| Zwischen verschiedenen AWS-Regionen | Höhere Kosten |
| Von AWS zur öffentlichen Cloud/Internet | Am teuersten |
Fazit:
Multi-AZ-Deployments sind im Vergleich zu Multi-Region-Strategien meist kosteneffizienter. Unternehmen müssen zwischen Kosten, Verfügbarkeit und Disaster Recovery-Zielen abwägen.
Wichtige Parameter bei der Wahl einer AWS-Region
Die Auswahl der richtigen AWS-Region und Availability Zone (AZ) ist entscheidend für die Performance, Kostenstruktur, Compliance und Servicequalität Ihrer Anwendung. Die folgenden vier Parameter helfen Ihnen, fundierte Entscheidungen zu treffen:
1. Latenz und geografische Nähe
Ziel: Optimale Performance durch geringe Netzwerklatenz
● Die Nähe zur AWS-Region hat einen direkten Einfluss auf Ladezeiten, Anwendungsreaktionen und Datenübertragung.
● Wählen Sie eine Region, die möglichst nah an Ihrem Hauptkundenstamm liegt.
● Beispiel: Liegt Ihr Kundenfokus in Nordamerika, bieten sich Regionen wie US East (N. Virginia) oder Canada Central an.
Vorteile:
✔ Geringere Latenz
✔ Bessere Nutzererfahrung
✔ Schnellere Datenübertragungen
2. Kostenstruktur
Ziel: Optimales Preis-Leistungs-Verhältnis
- AWS-Preise variieren je nach Region aufgrund unterschiedlicher Infrastruktur-, Energie- und Steuerkosten.
- Ein und derselbe Service kann in Asien deutlich teurer sein als in Europa oder den USA.
- Für größere Datenmengen können sich Preisunterschiede zwischen Regionen auf mehrere hundert Euro im Monat summieren.
Tipp: Nutzen Sie den AWS Pricing Calculator oder das NetApp AWS Calculator Tool, um die Gesamtkosten – einschließlich Speicher – realistisch zu kalkulieren
Vorteile:
✔ Transparente Planung
✔ Vermeidung versteckter Kosten
✔ Regionale Preisdifferenzen optimal nutzen
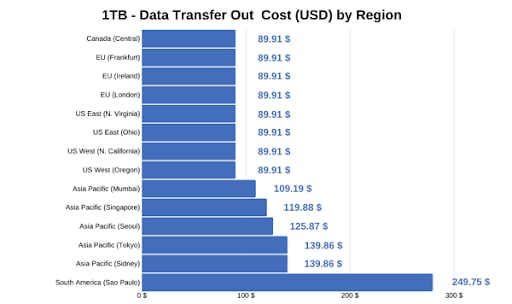
3. Compliance und Datenschutz
Ziel: Gesetzeskonformität und Schutz sensibler Daten
- Länder und Regionen wie die EU (DSGVO) oder USA (HIPAA, FedRAMP) haben unterschiedliche gesetzliche Vorgaben.
- Manche Regionen verbieten die Übertragung personenbezogener Daten außerhalb ihres Hoheitsgebiets.
- Achten Sie darauf, ob Ihre AWS-Region zertifiziert ist für relevante Compliance-Standards.
Risiken bei Nichteinhaltung:
✘ Bußgelder
✘ Rechtsstreitigkeiten
✘ Reputationsschäden
Empfehlung: Für global tätige Unternehmen ist eine Multi-Region-Strategie mit geo-spezifischen Datenhaltungskonzepten empfehlenswert.
4. Service Level Agreements (SLA) und Verfügbarkeit
Ziel: Hochverfügbarkeit und garantierte Betriebszeiten
● AWS garantiert Verfügbarkeiten je nach Service und Region (z. B. 99,99 % für EC2 in bestimmten Regionen).
● Voraussetzung: Die Architektur muss den AWS-Designrichtlinien für Hochverfügbarkeit entsprechen, z. B. durch Multi-AZ-Deployments.
● Prüfen Sie auch, ob Ihre gewählte Region Zugang zu allen gewünschten AWS-Services bietet (nicht alle Services sind global verfügbar).
Vorteile:
✔ Verlässliche Betriebszeit
✔ Klar definierte Wiederherstellungsziele (RTO/RPO)
✔ Passende Architektur für Ihre SLAs
Fazit: Die Wahl der richtigen Region hat weitreichende Auswirkungen auf Performance, Kosten, Sicherheit und regulatorische Konformität. Berücksichtigen Sie diese Parameter in Ihrer Cloud-Migrations- oder Skalierungsstrategie, um langfristig flexibel, sicher und effizient zu agieren.
Was ist ein Multi-AZ Deployment?
Ein Multi-AZ (Availability Zone) Deployment ist eine bewährte Methode zur Erreichung von Hochverfügbarkeit (High Availability, HA) in AWS-Umgebungen, insbesondere für unternehmenskritische Workloads wie Datenbanken, Geschäftsanwendungen oder Webplattformen.
Statt alle Ressourcen in nur einer einzigen Availability Zone (AZ) zu betreiben, werden Dienste und Daten auf mehrere, physisch getrennte AZs innerhalb einer Region verteilt. Damit wird sichergestellt, dass ein Ausfall einer gesamten AZ nicht zum vollständigen Ausfall der Anwendung führt.
Warum ist Multi-AZ wichtig?
Einzelne AZs sind zwar hochverfügbar, aber nicht ausfallsicher. Bei einem großflächigen Ausfall, z. B. durch Hardwareprobleme oder Netzwerkausfälle, kann ein Single-AZ-Deployment zu signifikanten Ausfallzeiten und Datenverlust führen.
Insbesondere für kritische Produktionssysteme gilt: Selbst kurze Ausfallzeiten sind inakzeptabel. Multi-AZ-Deployments bieten hier eine wirkungsvolle Absicherung.
Vorteile von Multi-AZ Deployments
-
Hochverfügbarkeit bei AZ-Ausfall: Anwendungen bleiben erreichbar, wenn eine Zone nicht mehr verfügbar ist.
-
Keine I/O-Verzögerungen bei Backups: Backups werden über die Standby-Instanz durchgeführt – ohne Auswirkungen auf die aktive Datenbankinstanz.
-
Keine Unterbrechungen bei Wartung oder Patches: Wartungsmaßnahmen erfolgen auf redundanten Instanzen, wodurch der Betrieb kontinuierlich weiterläuft.
-
Bessere Lastverteilung: Bei Lastspitzen in einer AZ können andere AZs sofort übernehmen – das verbessert die Reaktionsfähigkeit und Stabilität.
Typische Einsatzszenarien
Empfohlen:
- Produktionsdatenbanken (z. B. Amazon RDS, EC2-basierte Datenbanken)
- Geschäftskritische Webanwendungen
- Anwendungen mit hohen RTO-/RPO-Anforderungen
Nicht erforderlich:
- Entwicklungs- und Testumgebungen
- Kurzfristige temporäre Deployments
- Workloads mit extrem niedriger Latenzanforderung, bei denen Inter-AZ-Kommunikation zu viel Overhead erzeugt
Einschränkungen und Kostenaspekte
- Multi-AZ-Konfigurationen sind mit höheren Infrastrukturkosten verbunden, da Ressourcen redundant bereitgestellt werden.
- Nicht jede Anwendung profitiert davon – es ist wichtig, den kritischen Charakter des Workloads sorgfältig zu bewerten.
Fazit: Ein Multi-AZ-Deployment ist ein zentraler Bestandteil jeder hochverfügbaren Architektur in AWS. Für unternehmenskritische Anwendungen bietet es Schutz vor regionalen Ausfällen und minimiert das Risiko von Downtime und Datenverlust, ein klarer Mehrwert gegenüber Single-AZ-Deployments.
AWS Placement Groups: Strategische Instanzverteilung für Hochverfügbarkeit und Performance
AWS Placement Groups sind ein wichtiges Konfigurationsinstrument für Unternehmen, die bei der Platzierung von EC2-Instanzen gezielt auf Performance, Ausfallsicherheit oder Redundanz setzen. Sie ermöglichen eine flexible Verteilung von Instanzen auf physische Hosts innerhalb einer oder mehrerer Availability Zones (AZs), um bestimmte betriebliche Anforderungen optimal zu erfüllen.
AWS bietet drei Typen von Placement Groups, je nach Use Case und Architekturziel:
1. Cluster Placement Group
Ziel: Maximale Netzwerkleistung und minimale Latenz durch enge Platzierung
In einer Cluster Placement Group werden EC2-Instanzen so nah wie möglich zueinander auf demselben physischen Hardware-Rack innerhalb einer einzigen AZ platziert. Diese Anordnung eignet sich besonders für rechen- und netzwerkintensive Anwendungen, bei denen extrem geringe Latenz und hoher Durchsatz erforderlich sind.
Vorteile:
- Bis zu 10 Gbps Single-Flow und 25 Gbps aggregierte Netzwerkbandbreite
- Niedrige Latenz durch physische Nähe der Instanzen
- Optimale Bedingungen für parallele Verarbeitung
Geeignete Workloads:
- High Performance Computing (HPC)
- Genomforschung, Echtzeit-Streaming, Finanzsimulationen
- Wissenschaftliche Modelle wie Klima- oder Astrophysiksimulationen
2. Partition Placement Group
Ziel: Höhere Ausfallsicherheit durch physisch getrennte Partitionen
Instanzen werden in logisch getrennte Partitionen verteilt. Jede Partition wird auf einem separaten physischen Rack betrieben. Dadurch wird sichergestellt, dass ein Hardware-Ausfall nur einen Teil der Instanzen betrifft.
Vorteile:
- Minimierung des Risikos gemeinsamer Fehlerquellen
- Partitionierung sichtbar und steuerbar (z. B. für Hadoop oder Cassandra)
- Unterstützung für Single- und Multi-AZ-Deployments innerhalb einer Region
Geeignete Workloads:
- Verteilte Dateisysteme (z. B. HDFS, GlusterFS)
- NoSQL-Datenbanken wie Apache Cassandra
- Big Data Analytics und Reporting
- Elasticsearch- oder Indexing-Workloads
3. Spread Placement Group
Ziel: Höchste Redundanz für einzelne kritische Instanzen
Jede Instanz einer Spread Placement Group wird auf einem eigenen physischen Rack mit separater Stromversorgung und Netzwerkhardware platziert. Dies bietet die größtmögliche Redundanz auf Instanzebene, sowohl innerhalb einer einzelnen AZ als auch über mehrere AZs hinweg.
Vorteile:
- Reduziert das Risiko gleichzeitiger Ausfälle mehrerer kritischer Instanzen
- Flexible Verteilung über mehrere AZs
- Optimal für kleine, besonders geschäftskritische Komponenten
Geeignete Workloads:
- Kleine SQL-Datenbanken
- Webserver-Instanzen oder Applikationstiers mit Verfügbarkeitsanforderungen
- Komponenten, die nicht hohe Rechenleistung benötigen, aber maximale Ausfallsicherheit verlangen
Fazit:
Die Wahl des richtigen Placement-Group-Typs hängt stark vom Anwendungsszenario ab:
- Cluster für Performance
- Partition für Fehlertoleranz bei verteilten Workloads
- Spread für maximale Redundanz bei kritischen Einzelinstanzen
Ein durchdachtes Placement-Konzept ist entscheidend für die Resilienz und Performance Ihrer AWS-Workloads, insbesondere in Kombination mit weiteren HA-Strategien wie Multi-AZ-Deployments oder Cloud Volumes ONTAP.
Cloud Volumes ONTAP HA für AWS
Cloud Volumes ONTAP HA ist eine hochverfügbare Speicherlösung für AWS, die speziell für geschäftskritische Workloads entwickelt wurde. Sie basiert auf zwei Amazon EC2-Instanzen, zwischen denen alle Daten synchron gespiegelt werden. Die eigentliche Datenspeicherung erfolgt über Amazon EBS – durch die Spiegelung kann jedoch bei einem Ausfall in weniger als 60 Sekunden auf das Backup-System umgeschaltet werden, ohne Datenverlust.
Hochverfügbare Architektur
In der HA-Konfiguration von Cloud Volumes ONTAP arbeiten zwei Nodes entweder im Active-Active- oder Active-Passive-Modus:
- Active-Active: Beide Nodes bedienen parallel Clients.
- Active-Passive: Ein Node übernimmt aktiv den Betrieb, der zweite dient als Standby.
Unabhängig vom Modus werden alle neuen Schreibvorgänge synchron gespiegelt. Der Betrieb ist wahlweise in einem Single-AZ- oder Multi-AZ-Szenario möglich.
Bereitstellungsmöglichkeiten
Single-AZ-Konfiguration:
Beide Nodes befinden sich in derselben Availability Zone. NetApp Cloud Manager sorgt automatisch für eine Platzierung in einem Spread Placement Group-Setup, um das Risiko durch gemeinsame Hardwareausfälle zu minimieren.
Multi-AZ-Konfiguration:
Jeder Node befindet sich in einer anderen Availability Zone – so wird die AZ selbst als Single Point of Failure eliminiert. Diese Art der Konfiguration erfordert ein AWS Transit Gateway mit Floating IPs, um bei einem Ausfall den nahtlosen Failover-Prozess sicherzustellen. Damit ist ein durchgängiger NAS- oder Datenzugriff gewährleistet, selbst bei einer AZ-Störung.
Technische Anforderungen
Für den Betrieb von Cloud Volumes ONTAP HA sind drei EC2-Instanzen erforderlich:
- Zwei Storage-Nodes, die die Datenverarbeitung übernehmen
- Ein Mediator (t2.micro) zur Verwaltung des automatisierten Failovers und Failbacks
- Recovery Point Objective (RPO): 0 Sekunden – da alle Daten synchron gespiegelt werden
- Recovery Time Objective (RTO): < 60 Sekunden – Wiederherstellung im Fehlerfall nahezu sofort
Vorteile gegenüber nativen AWS-Storage-Optionen
Obwohl AWS über eigene Redundanzmechanismen auf Storage-Ebene verfügt, bringt Cloud Volumes ONTAP zusätzliche Vorteile:
| Funktion | Amazon EBS | Cloud Volumes ONTAP HA |
| AZ-übergreifende Replikation | ✘ | ✔ |
| Unterstützung für Windows und Linux | Eingeschränkt (EFS = NFS-only) | ✔ |
| RPO = 0 | ✘ (Snapshot-basiert) | ✔ (synchron gespiegelt) |
| Zentrale Verwaltung via NetApp Cloud Manager | ✘ | ✔ |
Beispiel: Um mit Amazon EBS eine vergleichbare Redundanz zu erzielen, müssten Snapshots manuell erstellt und in andere AZs übertragen werden – ein Prozess, der zusätzliche Kosten und Komplexität mit sich bringt.
Fazit
Cloud Volumes ONTAP HA bringt entscheidende Vorteile für den Aufbau einer hochverfügbaren, skalierbaren und kosteneffizienten Speicherarchitektur in AWS:
- Keine Datenverluste bei Ausfällen – dank synchroner Spiegelung
- Schnelle Wiederherstellung innerhalb von 60 Sekunden
- Flexible Bereitstellung in Single-AZ- oder Multi-AZ-Umgebungen
- Optimierte Kosten gegenüber reiner EBS-Nutzung
Für Unternehmen, die auf Geschäftskontinuität angewiesen sind, ist Cloud Volumes ONTAP HA eine leistungsfähige und zuverlässige Lösung, um zentrale Speicheranforderungen sicher und effizient in der Cloud umzusetzen.