AWS のリージョン、アベイラビリティゾーン、およびプレースメントグループの基礎知識
: AWS リージョンとアベイラビリティーゾーンの最適な活用法
このページを共有

Aviv Degani
AWS 高可用性ベストプラクティス:アベイラビリティーゾーンとプレースメントグループの活用
企業は、異なる可用性レベルや SLA(サービスレベルアグリーメント)の目標を持つアプリケーションを利用しています。アプリケーションの重要度や要求水準は、スループット、応答性、障害時の復旧時間といった要件に比例して判断されます。これらの考慮事項は、AWS における高可用性のベストプラクティスを策定する際にも当てはまります。
導入環境の具体的な要件に応じ、アベイラビリティーゾーン間にコンピュートとストレージを分散させ、プレースメントグループと組み合わせることで、この課題に対応可能です。さらに Cloud Volumes ONTAP HA を導入することで、各レイヤーの要件を満たす最適な構成を実現できます。
本記事では、単一および複数のアベイラビリティーゾーン、プレースメントグループを活用した AWS 高可用性のベストプラクティスとユースケースを解説します。加えて、ストレージレベルのソリューションとして Cloud Volumes ONTAP HA がもたらすメリットについても紹介します。
AWS リージョンとアベイラビリティゾーンの概要
アベイラビリティゾーン(Availability Zone, AZ)は、各 AWS リージョン内に設置された高可用性のデータセンターです。リージョンは独立した地理的エリアを表し、それぞれの AZ は独自の電源設備・冷却システム・ネットワークを備えています。
ある AZ 全体が停止した場合でも、AWS は同一リージョン内の別の AZ にワークロードをフェイルオーバーできます。この仕組みを「マルチAZ冗長化」と呼びます。
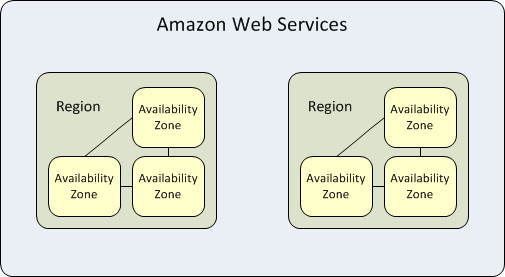
AWS リージョン
各 AWS リージョンは他のリージョンから隔離され、独立して運用されています。同一リージョン内の AZ 間は低レイテンシーのリンクで接続されており、レプリケーションやフォールトトレランスを実現します。
もしすべてのデータやインスタンスを 1 つの AZ にのみ配置している場合、その AZ に障害が発生すると、データやインスタンスは利用できなくなります。
この隔離設計の目的は、データ主権やコンプライアンス要件が厳格で、ユーザーデータを特定の地理的リージョン外に持ち出すことを許さないワークロードをサポートすることにあります。こうしたワークロードは、低レイテンシーで他リージョンから完全に分離された AWS アベイラビリティゾーン構造の利点を享受できます。
AWS グローバルインフラストラクチャにおける利用可能なリージョンの一覧については、公式リストをご参照ください。
AWS リージョンとアベイラビリティーゾーンの違い
AWS リージョン間でワークロードを実行する場合と、同一リージョン内の異なるアベイラビリティーゾーン(AZ)で実行する場合には、2 つの主要な運用上の違いがあります。
地理的分散
AWS リージョンと AZ の地理的分散は、アプリケーションのパフォーマンスと信頼性に大きな影響を与えます。単一リージョン内の複数 AZ にアプリケーションをデプロイすると、高可用性とフォールトトレランスを実現できます。1つの AZ に障害が発生しても、アプリケーションは別の AZ 上で中断なく稼働し続けます。ただし、リージョン全体が停止した場合、アプリケーションも停止します。
複数のリージョンにアプリケーションを分散してデプロイすると、リージョン全体が停止するまれな事態でもサービスを継続可能です。また、複数リージョンに展開することで、グローバルユーザー向けのレイテンシー低減や、迅速なディザスタリカバリといった追加のメリットも得られます。
コンピューティングコストとデータ転送料金
リージョンの選択はコストに影響します。各リージョンの料金は、需要、インフラ運用コスト、現地の税制などによって異なります。例えば、アジアパシフィック(ムンバイ)リージョンで EC2 インスタンスを稼働させる場合、米国東部(バージニア北部)リージョンより料金が高くなることがあります。ただし、同一リージョン内の複数アベイラビリティゾーン(AZ)にワークロードを分散しても、コストは概ね同等です。
また、データ転送料金は、同一リージョン内、異なるリージョン間、あるいはリージョンとインターネット間で異なります。同一リージョンや AZ 間のデータ転送は比較的安価ですが、リージョン間やインターネットへの転送は高額になりやすい傾向があります。
AWS リージョン選択時の考慮事項
アプリケーションをホスト・デプロイする際に、AWS リージョンやアベイラビリティゾーン(AZ)を選択する場合、いくつかの重要なパラメーターを考慮する必要があります。以下に、特に重視すべきポイントを示します。
パラメーター 1:レイテンシーと地理的近接性
低レイテンシーを実現するには、ユーザーの大多数に最も近いリージョンを選択することが推奨されます。サーバーとの接続が速いほど、読み込み速度やデータ転送時間が短縮され、ユーザー体験が大幅に向上します。
例えば、顧客の大半が北米からアクセスしている場合は、米国またはカナダのリージョンを選択するのが最適です。クラウドとエンドユーザー間の距離が短いほど、レイテンシーは低くなります。
パラメーター 2:コスト
AWS サービスの料金は、物理インフラのコストや税制により、リージョンごとに異なります。リージョン間で数百ドルの料金差が生じる場合もあり、コスト削減には適切なリージョン選択が重要です。
AWS 公式料金計算ツールで最適なリージョンを確認できます。さらに、NetApp の AWS Calculator を使えば、ストレージサービス費用を含む TCO(総所有コスト)も算出可能です。
(参考表:1TB のデータ転送に関するリージョンごとの料金比較)
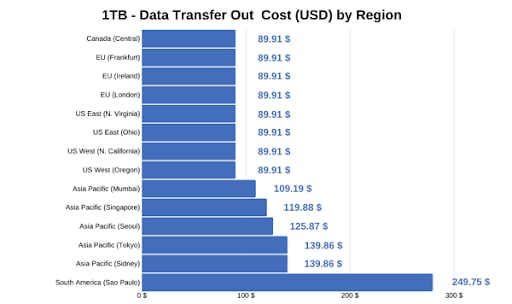
パラメーター 3:規制遵守とセキュリティ
各国・地域(例:EU)には、ユーザーデータ保護の独自のコンプライアンス基準があります。一部のリージョンでは、他リージョンへのデータ転送が禁止されており、違反すると法的リスクや大きな金銭・信用の損失につながります。
グローバルに展開する企業は、複数の AWS リージョンやアベイラビリティゾーン(AZ)を活用し、世界中の顧客に高速かつ信頼性の高いサービスを提供できるよう検討するとよいでしょう。
パラメーター 4:サービスレベルアグリーメント(SLA)
各サービスは、固有の可用性と設計に基づく SLA を提供しています。AWS の設計に沿ってアプリケーションをデプロイすると、最適な SLA の恩恵を受けられます。
リージョンやアベイラビリティゾーン(AZ)の選定では、これまでのパラメーターを総合的に考慮し、自社の要件に最適な環境を選ぶことが重要です。
マルチ AZ デプロイメントとは
エンタープライズ向けデータベースのようなミッションクリティカルなワークロード(Amazon EC2 インスタンスや Amazon RDS などの AWS ネイティブデータベースサービス)では、マルチ AZ 配置モデルを採用することで、アベイラビリティゾーン(AZ)全体に重大な障害が発生しても高可用性を確保できます。
本番アプリケーションでは、ダウンタイムを最小限に抑えるため、こうした大規模障害を現実的なリスクとして考慮し、マルチ AZ 配置を検討することが重要です。
例えば、ウェブサービス層がすべて単一 AZ にホストされている場合、データベース層が HA 構成でマルチ AZ に分散されていても、ウェブ層が単一 AZ に依存している限り、高可用性の効果は限定的です。
高可用性の観点では、単一 AZ デプロイメントでは、その AZ が停止するとすべてが停止し、リカバリータイム目標(RTO)が大幅に延びます。加えて、その間にデータ損失が発生する可能性もあります。
マルチ AZ デプロイメントの主な利点
- バックアップ時の I/O 遅延が発生しない — スタンバイインスタンスからバックアップを取得するため、本番稼働に影響がありません。
- メンテナンス時も I/O が中断されない — パッチ適用やアップグレードの際にもサービスが継続可能です。
- 負荷分散による応答性向上 — 1 つの AZ に制約が発生しても、他の AZ のインスタンスがトラフィックを処理できます。
ただし、すべてのアプリケーションがマルチ AZ を必要とするわけではありません。短期的なテストや開発環境など、クリティカルでないユースケースは単一 AZ にホストしてコストを抑えることができます。超低レイテンシーが求められる特殊なケースでは、単一 AZ モデルの方が適していることもあります。
AWS プレースメントグループの概要
プレースメントグループは、AWS が提供する構成オプションの一つで、相互に依存する複数のインスタンスを基盤ハードウェア上で特定の方法に従って配置できる仕組みです。
インスタンスは互いに近接して配置したり、異なるラックやアベイラビリティゾーン(AZ)に分散させたりすることが可能です。
以下では、選択できる各プレースメントグループの種類と、それぞれに適したワークロードについて詳しく見ていきます。
クラスタープレースメントグループ
クラスタープレースメントグループを利用すると、相互に関連するインスタンスを物理的に近接させて配置することで、高スループットと低レイテンシーを実現できます。インスタンスは同一アベイラビリティゾーン(AZ)内に集約して配置する必要があり、同一 VPC 内やピアリングされた VPC 間で利用可能です。
利点としては、インスタンス間通信が従来の単一フローあたり5 Gbpsに制限されず、単一フロー(ポイントツーポイント)で最大10 Gbps、集約トラフィック全体で最大25 Gbpsを実現できる点です。
このモデルは、ハイパフォーマンスコンピューティング(HPC)系のネットワーク集約型アプリケーションに最適です。具体例としては、計算工学、ライブイベントのストリーミング、ゲノム解析、天文学モデル、気候シミュレーションなどが挙げられます。
パーティションプレースメントグループ
パーティションプレースメントグループでは、インスタンス群を複数の論理パーティションに分割して配置します。各論理パーティションは異なるハードウェアラック上に配置されるため、共通のハードウェア障害を回避できます。1台のラックに障害が発生しても、影響を受けるのはそのラック上のパーティション内のインスタンスだけです。
各論理パーティションは複数のインスタンスで構成され、同一アベイラビリティゾーン(AZ)内に配置することも、同一リージョン内のマルチ AZ 環境にまたがって配置することも可能です。
このモデルは、分散およびレプリケーションを必要とするビッグデータストアに最適です。代表的な例としては、大規模ファイルシステムの HDFS や Cassandra があります。パーティションプレースメントグループを利用すると、インスタンスの配置を把握でき、Hadoop や Cassandra のトポロジーに応じてデータレプリケーションを適切に設定できます。その他にも、ビッグデータ分析、データレポーティング、大規模インデックス作成などのユースケースに適しています。
スプレッドプレースメントグループ
スプレッドプレースメントグループでは、各インスタンスがそれぞれ独立した物理ラック上で稼働します。たとえば5台のインスタンスを配置すると、それぞれ異なるラックに割り当てられ、独自のネットワーク接続と電源を持ちます。この構成は単一アベイラビリティゾーン(AZ)内でも、マルチ AZ アーキテクチャでも実現可能です。
スプレッドプレースメントグループはパーティションプレースメントグループに似ていますが、主な違いは「単一インスタンスを異なるラックや AZ に分散させる」点です。
このモデルは、ビジネス上クリティカルな少数のインスタンスに最適です。代表例としては、少数の SQL データベースインスタンスや Web アプリケーションのフロントエンド層などがあります。大規模計算を必要とするクラスタ型やパーティション型と異なり、スプレッドプレースメントグループは冗長性確保に重点を置くユースケースに最適です。
AWS 向け Cloud Volumes ONTAP HA
Cloud Volumes ONTAP の HA(High Availability)構成は、AWS 上で高可用性を提供します。Amazon EC2 の 2 ノード構成で稼働し、データは Amazon EBS に保存されるため、障害発生時もデータ損失を防ぎ、60 秒以内に復旧可能です。
- 構成
- アクティブ–アクティブ:両ノードがサービスを提供
- アクティブ–パッシブ:片方がスタンバイ
- いずれもデータ書き込み時に同期ミラーリングされます
- 導入可能シナリオ
- 単一 AZ またはマルチ AZ
単一 AZ:両ノードを同一 AZ に配置。NetApp Cloud Manager により自動的にスプレッドプレースメントグループ構成でデプロイされ、共通の障害を回避。
マルチ AZ:各ノードを異なる AZ に配置。AZ 全体の障害を単一障害点にせず、AWS Transit Gateway とフローティング IP の設定でフェイルオーバーと恒久的な NAS アクセスを提供。
ノード構成
- メインノード ×2:ストレージ処理
- t2.micro メディエーターインスタンス ×1:フェイルオーバー/フェイルバック制御
RPO(Recovery Point Objective):ゼロ(同期ミラーリングで常にデータ一貫性を保持)
RTO(Recovery Time Objective):60 秒以下(フェイルオーバー後も 1 分以内に再アクセス可能)
補足
Amazon EBS は単一 AZ 内でのみレプリケーション可能で、別 AZ へ冗長化するには S3 スナップショットが必要です。Amazon EFS は NFS を介したアクセスのみで、Windows インスタンスは未対応です。
まとめ
本記事で解説した AWS 高可用性のベストプラクティスから、以下の 3 つの主要な結論が導き出されます。
- マルチ AZ 構成を導入することで、アベイラビリティーゾーン全体を単一障害点から排除でき、信頼性が一段と向上する。
- ワークロードごとに要件は異なるため、単一 AZ デプロイメントとマルチ AZ デプロイメントのどちらが適しているかを適切に判断する必要がある。
- 集中型ストレージが必要な場合、Cloud Volumes ONTAP HA はストレージレベルで冗長性と迅速な復旧を実現。単一 AZ でもマルチ AZ でも利用可能である。Amazon EBS 単体で運用する場合と比較して、同等もしくはそれ以下のコストで提供される。
事業継続性はあらゆる企業にとって重要です。Cloud Volumes ONTAP を活用することで、高い可用性と信頼性を確保し、企業のビジネス継続を支えることができます。