S3 Intelligent-Tiering 的 Archive Instant Access Tier
分享本頁

Sudip Sengupta
Amazon Web Services (AWS) 為用戶提供了豐富的選擇,幫助他們找到兼顧成本和效能的最佳儲存方案。其中最受歡迎的 S3 儲存類別之一是 S3 Intelligent-Tiering,自推出以來已幫助客戶節省了 7.5 億美元的儲存成本。
S3 Intelligent-Tiering 可根據存取頻率在不同的儲存層之間移動物件,從而最佳化儲存成本。隨著 AWS 近期推出的 Archive Instant Access 層,Intelligent-Tiering 現在可以自動歸檔資料以降低成本,同時提供亞毫秒的檢索存取速度。
在本文中,我們將了解 S3 Intelligent-Tiering 的 Archive Instant Access 層、其優勢和各種使用案例。
- 什麼是 S3 中的智慧分層?
- S3 Intelligent-Tiering Archive Instant Access 使用案例
- 如何啟用 S3 Intelligent Tiering
- 利用 BlueXP Cloud Volumes ONTAP 擴展 S3 Intelligent-Tiering 的優勢
- 常見問題集
S3 中的 Intelligent Tiering 是什麼?
Amazon S3 Intelligent-Tiering 是一種基於雲端的物件儲存類別,它會自動將物件歸檔到經濟高效的儲存層,從而最大限度地提高成本效益。憑藉其智慧演算法,Intelligent-Tiering 可自動幫助您優化儲存成本,同時不會犧牲效能或可用性。雖然此儲存類別非常適合具有未知或不斷變化的資料使用模式的資料,例如應用程式日誌、媒體檔案和感測器資料,但它也可用於存取頻率高但對延遲要求不高的資料,例如備份和災難復原檔案。
S3 Intelligent-Tiering 持續監控您的資料使用情況,並根據存取模式自動在熱儲存、溫儲存和冷儲存三個層級之間進行切換。熱儲存層針對頻繁存取的資料進行了最佳化,而溫儲存層和冷儲存層則針對不頻繁或極少存取的資料而設計。其主要優點之一是,您只需為實際使用的儲存空間付費,外加少量用於監控和自動化的月費。
Archive Instant Access 層級的運作方式
Archive Instant Access (AIA) 儲存層可為不常存取的資料提供快速擷取時間,同時仍能提供雲端儲存的成本效益。與 Infrequent Access (IA) 層相比,Archive Instant Access 層可讓客戶在不影響可用性或持久性的情況下歸檔資料,因為他們知道可以即時擷取所需的資料,而無需先從較低層還原。
對於 S3 Intelligent-Tiering 類別中的所有儲存物件,AIA 層會自動啟用。在 IA 層中,任何 90 天未被存取的資料物件都會自動遷移到 AIA 層。此外,此儲存層還允許根據需要將資料轉換回 Standard 儲存層或 Bulk 儲存層,而無需預先投資。
S3 Intelligent Tiering Archive Instant Access Tier 的優勢
使用 S3 Intelligent-Tiering AIA 層的好處包括:
無需支付檢索費用
雖然 Amazon S3 會為從歸檔層匯出的資料付費,但您只需為實際使用的容量付費。因此,重建或檢索歸檔在 AIA 層中的資料不會產生任何費用。這使其成為不常存取但仍需快速存取且無需額外費用的資料的理想儲存解決方案。
無最短儲存期限
S3 Intelligent-Tiering AIA 層沒有最短儲存期限。您可以根據需要在此層儲存物件,時長可長可短,無需擔心任何最短期限。這使其成為儲存您可能不需要立即存取但仍希望保留以備將來使用的資料的理想選擇。您只需為使用的儲存空間付費,因此您可以僅儲存將來需要的資料,從而最大限度地降低成本。
零運維開銷
S3 Intelligent-Tiering 演算法利用機器學習技術監控存取模式,並即時決策,為每個物件確定最佳儲存層。這意味著您無需再手動在不同儲存層之間移動物件,也無需為不必要的儲存空間付費。這與其他需要管理員介入和定期調優才能保持最佳效能和成本效益的儲存解決方案截然不同。
此外、AIA 層可減少在擷取之前跨層移動物件所涉及的工作量,進而提供對歸檔資料的即時存取能力。
低延遲和高吞吐量
AIA 層依賴 S3 的基礎技術,包括資料本地化、多可用區、優化的檔案系統和高效的快取機制,從而降低延遲。這種設計模式使儲存層即使對於存取頻率極低的資料也能提供亞毫秒級的檢索速度。
此外,儲存層還採用硬碟(HDD)和固態硬碟(SSD)的最佳組合,以實現高吞吐量。這使其非常適合依賴高效能儲存的工作負載,例如視訊串流或大數據分析。
S3 Intelligent-Tiering Archive Instant Access 使用案例
Amazon S3 的 Intelligent-Tiering AIA 層最適合不常存取但仍需要在需要時快速可用的資料。這包括備份、日誌檔案和媒體檔案等資料。Archive 層的每 GB 價格低於 Standard 儲存類別,使其更具成本效益以進行長期儲存。而且,由於它仍在 S3 中,您可以利用使用 S3 所帶來的所有優勢,例如安全性和持久性。
AIA 層的一些適當使用案例包括:
不常存取的歸檔儲存
AIA 層的一個常見使用案例是儲存不常存取的資料。儲存和擷取的低成本使此層級非常適合歸檔資料,因為可以長期儲存而不會產生高成本。此外,此層級的高耐用性意味著即使很少存取,資料也會安全且可存取。
快速存取儲存層
AIA 層的另一個常見用途是儲存需要快速存取的資料。使用此層儲存此類資料的主要優勢在於其快速存取速度。這意味著使用者無需等待從速度較慢的儲存媒體中檢索資料,即可存取所需資料。此外,該層的高持久性意味著即使頻繁存取,資料也能保持安全且易於存取。
適用於不可預測的存取模式
AIA 層非常適合存取模式隨時間不可預測變化的儲存物件。例如,在音樂唱片收藏和串流應用程式中,使用者經常存取最近上傳的音樂。隨著唱片時間的推移,串流趨勢會逐漸減少。在幾個月沒有存取之後,S3 的 Intelligent-Tiering 可以將音訊檔案移至 AIA 層。藝術家人氣的突然飆升可能會導致對其較舊音樂的興趣增加,然後可以透過 AIA 層立即檢索這些資料進行串流播放,或者可以根據存取模式遷移到頻繁存取層。
如何啟用 S3 Intelligent Tiering
要開始使用 Intelligent-Tiering,首先需要建立一個新的儲存類別。您可以使用 S3 Console、AWS CLI 或 PUT API 物件來完成此操作。建立儲存類別後,即可使用簡單的 API 呼叫將資料移至該儲存類別。
注意:S3 Intelligent-Tiering 現在會自動將 IA 層中 90 天內未被存取的任何物件分層到 AIA 層。若要手動配置儲存桶中各個物件的規則,您可以依照下列步驟操作。
使用 S3 Console
在儲存桶物件層級套用分層策略之前,請導覽至 S3 控制台並選擇要啟用 Intelligent-Tiering 的儲存桶。然後,選擇 Management 標籤並點擊 Intelligent-Tiering。您可以在此處檢查是否啟用了 Automatic 或 Manual 模式。啟用 Automatic 模式後,S3 會根據使用模式自動在不同層級之間移動物件。使用 Manual 模式,您可以指定物件應儲存在哪個層級。
假設您打算對現有儲存貯體中的各個物件套用分層規則。為此,請按照以下工作流程操作:
- Sign in 至 AWS S3 控制台,然後從 S3 儲存桶清單中選擇目標儲存桶。
- 選擇 Properties 標籤。
- 前往 S3 Intelligent-Tiering Archive configurations 部分,然後選擇「Create configuration」按鈕。

- 現在您將進入 Archive configuration settings 部分。請輸入組態名稱,並決定該組態是套用於整個儲存桶還是單一物件。在本例中,我們選擇將規則套用至單一物件。
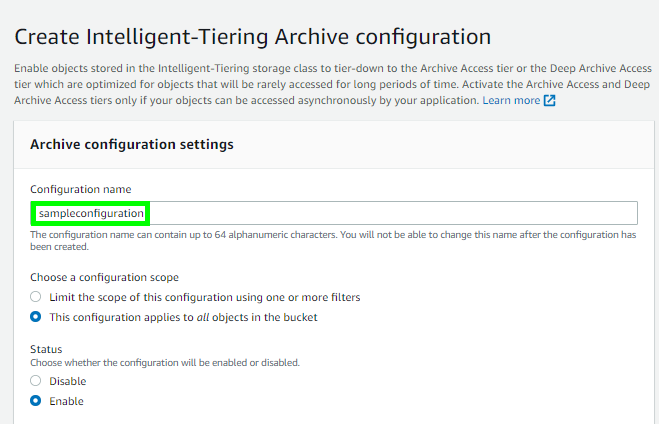
- 按一下 Create 以確認組態,成功建立後會顯示在 S3 主控台中。

使用 Amazon CLI
您也可以使用 AWS CLI 命令來管理 S3 Intelligent 層的設定。
典型的做法是使用 put-bucket-intelligent-tiering-configuration 命令,並將設定指定為 JSON 檔案,以啟用不同的分層選項。以下命令將 AIA 設定指派給 darwinbucketexample 儲存貯體。
$ put-bucket-intelligent-tiering-configuration
{ 「Id」: 「darwinbucketexample」, 「Filter」: { 「Prefix」: 「filter-criteria1」, 「Tag」: { "Key": "object-tag-key1", "Value": "object-tag1" }, 「And」: { 「Prefix」: 「filter-criteria2」, 「Tags」: [ { "Key": "object-tag-key2", "Value": "object-tag2" } ...] } }, 「Status」: 「Disabled」 「Tierings」: [ { "Days": integer, "AccessTier": "ARCHIVE_ACCESS"\|"DEEP_ARCHIVE_ACCESS" } ...]}
使用 PUT API 操作
您也可以使用 PUT API 物件來套用規則,以控制資料如何移至 S3 Intelligent-Tiering,然後進行歸檔。
例如,要將 darwinbucketexample 儲存貯體移至 Intelligent-Tiering,您必須在 x-amz-storage-class 標頭下將 INTELLIGENT_TIERING 包含為儲存類別。
PUT /darwin-image.jpg HTTP/1.1Host: darwinbucketexample.s3..amazonaws.com(http://amazonaws.com/)Date: Thu, 22 Dec 2021 15:50:33 GMTAuthorization: authorization stringContent-Type: image/jpegContent-Length: 22452Expect: 100-continuex-amz-storage-class: INTELLIGENT_TIERING
完成後,您可以使用 PutBucketIntelligentTieringConfiguration API 操作為特定儲存桶或儲存桶物件配置 Intelligent-Tiering 的歸檔規則。
利用 BlueXP Cloud Volumes ONTAP 擴展 S3 Intelligent-Tiering 的優勢
雖然 S3 Intelligent-Tiering 為 S3 使用者增加了一項急需的功能,NetApp BlueXP Cloud Volumes ONTAP 可以將其進一步發展為 AWS 的資料管理層。
Cloud Volumes ONTAP 資料分層功能可將不常用的 EBS 儲存資料自動分層到更經濟高效的 S3 Intelligent-Tiering 儲存中,並在需要時自動將其移回。在 AWS 上,物件儲存和區塊儲存之間的分層儲存並非原生支援。
但這還不是全部優勢。Cloud Volumes ONTAP 利用更經濟高效且節省空間的NetApp Snapshot 技術和Cloud Backup,為 AWS 使用者提供更高層級的資料保護。內建的儲存效率提升功能(包括重複資料刪除、壓縮和精簡配置)不僅可以降低 S3 的整體儲存成本,還可以降低成本更高的AWS EBS 儲存成本。此外,BlueXP replication(含SnapMirror®)讓您輕鬆有效率地在 AWS 區域、本地部署甚至不同雲端平台之間遷移資料。
透過這些 Cloud Volumes ONTAP 儲存分層案例研究,深入了解 Cloud Volumes ONTAP 如何提供協助。
常見問題集
如何在 S3 儲存桶上啟用 Intelligent-Tiering?
若要在 S3 儲存桶上啟用 Intelligent-Tiering,請先從儲存桶清單中選擇儲存桶名稱。在儲存桶頁面上,選擇 Properties,捲動至 S3 Intelligent-Tiering Configurations 部分,然後按一下 Create。有關 S3 儲存桶 intelligent-tier 配置設定的更多詳細資訊,請參閱 AWS 官方文件。
S3 Intelligent-Tiering 收費貴嗎?
雖然 S3 Intelligent-Tiering 的初始成本可能較高,但從長遠來看,它最終可以為企業節省資金。透過 S3 Intelligent-Tiering,資料會自動遷移到最具成本效益的儲存層,從而降低儲存成本。這通常是透過根據存取模式自動將資料儲存在最合適的儲存類別中來實現的,因此非常適合存取頻率較低的資料。此外,S3 Intelligent-Tiering 還能提供額外的資料遺失和損壞防護,進而進一步降低緊急成本。