S3 Intelligent-Tiering の Archive Instant Access 階層
このページを共有

Sudip Sengupta
Amazon Web Services(AWS)は、コストとパフォーマンスの最適化を目的とした多様なストレージオプションを提供しています。中でも S3 Intelligent-Tiering は、最も人気のある S3 ストレージクラスのひとつであり、提供開始以降、累計 7億5,000万ドル以上のストレージコスト削減 に貢献してきました。
S3 Intelligent-Tiering は、アクセス頻度に応じてオブジェクトを異なるストレージ階層へ自動的に移動することで、ストレージコストを最適化します。AWS が新たに提供を開始した Archive Instant Access(AIA)階層 により、データを自動的にアーカイブしながら、サブミリ秒レベルの即時アクセス を実現できるようになりました。
本記事では、S3 Intelligent-Tiering の Archive Instant Access 階層の仕組み、メリット、そして代表的なユースケースについて解説します。
S3 における Intelligent-Tiering とは?
Amazon S3 Intelligent-Tiering は、クラウドベースのオブジェクトストレージクラスで、データをコスト効率の高いストレージ階層へ自動的に移動・アーカイブします。インテリジェントなアルゴリズムにより、パフォーマンスや可用性を犠牲にすることなく、ストレージコストを最適化 できます。
このストレージクラスは、アプリケーションログ、メディアファイル、センサーデータなど、アクセスパターンが不明または変動するデータ に最適です。また、バックアップや災害復旧(DR)データのように、低レイテンシを必ずしも必要としない頻繁にアクセスされるデータにも利用できます。
S3 Intelligent-Tiering はデータ使用状況を継続的に監視し、アクセスパターンに応じて ホット(高頻度)、ウォーム(低頻度)、コールド(ほぼ未使用) の3つの階層間で自動的にデータを移動します。
主なメリットのひとつは、実際に使用したストレージ容量と、わずかな月額の監視・自動化料金のみを支払う という点です。
Archive Instant Access 階層の仕組み
Archive Instant Access(AIA)階層 は、アクセス頻度の低いデータに対して、高速な取得性能とクラウドストレージのコストメリットを両立させるストレージ階層です。
従来の Infrequent Access(IA)階層と比較すると、AIA 階層では 可用性や耐久性を損なうことなくデータをアーカイブ でき、必要なときに 事前のリストアなしで即座に取得 できます。
AIA 階層は S3 Intelligent-Tiering クラス内のすべてのオブジェクトに自動的に適用され、90日間アクセスされなかった IA 階層のデータは自動的に AIA 階層へ移動 されます。また、必要に応じて Standard や Bulk ストレージ階層へ柔軟に戻すことも可能で、初期投資は不要です。
S3 Intelligent-Tiering Archive Instant Access 階層のメリット
取得(リトリーバル)料金なし
Amazon S3 がアーカイブ階層からのデータ送信(エグレス)を負担するため、AIA 階層に保存されたデータの復元や取得に追加料金は発生しません。
これにより、低頻度アクセスでありながら迅速な取得が求められるデータに最適なストレージとなります。
最小保存期間なし
S3 Intelligent-Tiering AIA 階層には 最小保存期間の制限がありません。短期間・長期間を問わず自由にデータを保存でき、将来必要になる可能性のあるデータの保持に適しています。使用した分だけ支払うため、無駄なコストを抑えられます。
運用負荷ゼロ
S3 Intelligent-Tiering は、機械学習を活用してアクセスパターンを監視し、各オブジェクトに最適なストレージ階層をリアルタイムで判断します。そのため、手動での階層管理やチューニングは不要 です。
さらに、AIA 階層では、データ取得前に階層間移動を行う必要がなく、アーカイブデータへの即時アクセスが可能です。
低レイテンシと高スループット
AIA 階層は、データローカリティ、複数アベイラビリティゾーン、最適化されたファイルシステム、高効率キャッシュなど、S3 の基盤技術を活用し、サブミリ秒の取得性能 を実現します。
また、HDD と SSD を最適に組み合わせることで高スループットを実現し、動画配信やビッグデータ分析 などの高性能ワークロードにも適しています。
S3 Intelligent-Tiering Archive Instant Access のユースケース
S3 Intelligent-Tiering AIA 階層は、低頻度アクセスだが即時利用が求められるデータ に最適です。バックアップ、ログファイル、メディアデータなどが代表例です。Standard ストレージより GB 単価が低く、長期保存に向いています。
低頻度アクセスのアーカイブストレージ
長期間アクセスされないデータを低コストで保存でき、高い耐久性により安全性も確保されます。
高速アクセスが必要なデータ
必要時にすぐアクセス可能なため、緊急時や突発的な利用にも対応できます。
予測困難なアクセスパターン
音楽配信サービスのように、新曲は頻繁に再生され、時間の経過とともにアクセスが減少するケースに最適です。突然の人気再燃時でも、AIA 階層から即座にデータを取得できます。
S3 Intelligent-Tiering の有効化方法
S3 Intelligent-Tiering を利用するには、新しいストレージクラスを作成します。これは S3 コンソール、AWS CLI、PUT API から実行できます。
※ IA 階層で 90 日間アクセスされなかったオブジェクトは、自動的に AIA 階層へ移動されます。個別オブジェクトに対して手動設定する場合は以下の手順を実行します。
S3 コンソールを使用する方法
バケット内のオブジェクトレベルで階層化ポリシーを適用する前に、まず S3 コンソール にアクセスし、Intelligent-Tiering を有効化したいバケットを選択します。
次に 「Management」タブ を選択し、「Intelligent-Tiering」 をクリックします。ここで 自動(Automatic)モード または 手動(Manual)モード が有効になっているかを確認できます。
自動モードでは、S3 がアクセスパターンに基づいてオブジェクトをストレージ階層間で自動的に移動します。
手動モードでは、各オブジェクトをどの階層に保存するかを明示的に指定できます。
ここでは、既存のバケット内の 個別オブジェクト に対して階層化ルールを適用するケースを想定します。以下の手順に従って設定を行ってください。
- AWS S3 コンソール にサインインし、S3 バケット一覧から対象のバケットを選択します。
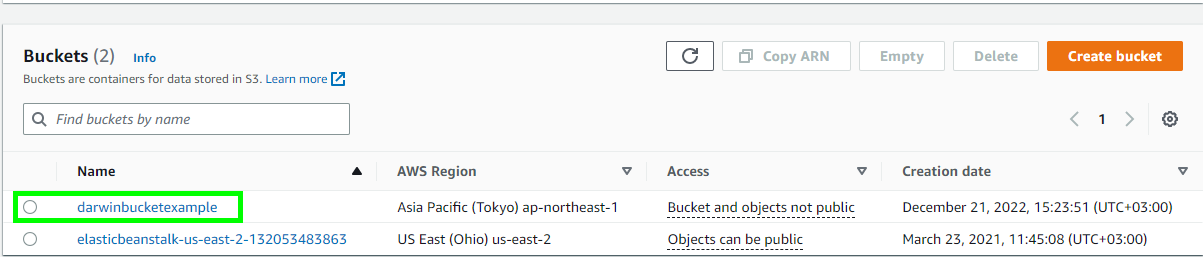
- 「Properties」タブ を選択します。
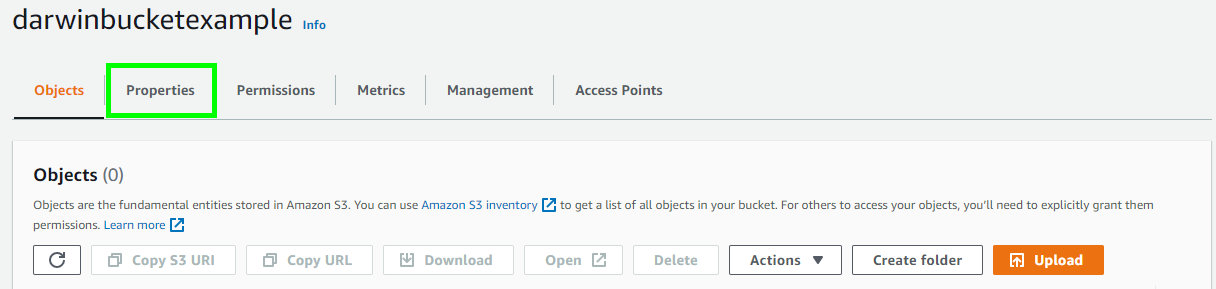
- 「S3 Intelligent-Tiering Archive configurations」 セクションへ移動し、「Create configuration」 ボタンをクリックします。

- 「Archive configuration settings」 画面が表示されます。
設定名を入力し、この設定を バケット全体 に適用するか、個別オブジェクト に適用するかを選択します。• 本例では、個別オブジェクトへの適用を選択しています。
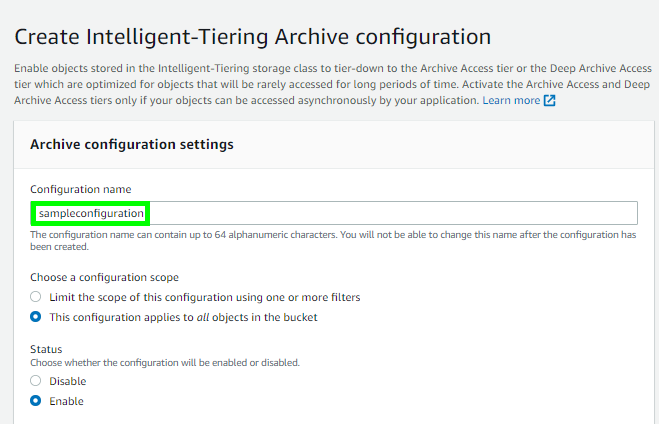
- 「Create」 をクリックして設定を確定します。
設定が正常に作成されると、S3 コンソール上に表示されます。

AWS CLI を使用する方法
AWS CLI コマンドを使用して、S3 Intelligent-Tiering の設定を管理することも可能です。
一般的な方法としては、put-bucket-intelligent-tiering-configuration コマンドを使用し、JSON ファイル形式で設定を指定することで、さまざまな階層化オプションを有効化します。
以下の例では、AIA(Archive Instant Access)設定 をdarwinbucketexample バケットに適用しています。
$ put-bucket-intelligent-tiering-configuration
{ "Id": "darwinbucketexample", "Filter": { "Prefix": "filter-criteria1", "Tag": { "Key": "object-tag-key1", "Value": "object-tag1" }, "And": { "Prefix": "filter-criteria2", "Tags": [ { "Key": "object-tag-key2", "Value": "object-tag2" } ... ] } }, "Status": "Disabled" "Tierings": [ { "Days": integer, "AccessTier": "ARCHIVE_ACCESS"\|"DEEP_ARCHIVE_ACCESS" } ... ]}
PUT API を使用する方法
PUT API を使用して、S3 Intelligent-Tiering へのデータ移動およびアーカイブルールを設定することもできます。
たとえば、darwinbucketexample バケットを Intelligent-Tiering に移行する場合、x-amz-storage-class ヘッダーに INTELLIGENT_TIERING を指定します。
PUT /darwin-image.jpg HTTP/1.1Host: darwinbucketexample.s3..amazonaws.com (http://amazonaws.com/)Date: Thu, 22 Dec 2021 15:50:33 GMTAuthorization: authorization stringContent-Type: image/jpegContent-Length: 22452Expect: 100-continuex-amz-storage-class: INTELLIGENT_TIERING
設定完了後、PutBucketIntelligentTieringConfiguration API オペレーションを使用して、特定のバケットまたはバケット内オブジェクトに対するアーカイブルールを構成できます。
BlueXP Cloud Volumes ONTAP による S3 Intelligent-Tiering の拡張
S3 Intelligent-Tiering は S3 ユーザーにとって非常に有用な機能ですが、NetApp BlueXP Cloud Volumes ONTAP を利用することで、AWS 上のデータ管理をさらに高度化できます。
Cloud Volumes ONTAP のデータ階層化機能により、低頻度で使用される EBS ストレージデータを、自動的により低コストな S3 Intelligent-Tiering へ移動 し、必要に応じて自動で戻すことが可能です。
AWS ネイティブでは、オブジェクトストレージとブロックストレージ間の階層化は実現できません。
さらに、Cloud Volumes ONTAP は、NetApp Snapshot 技術 や Cloud Backup を活用することで、より高いレベルのデータ保護を提供します。
重複排除、圧縮、Thin Provisioning などの組み込みストレージ最適化機能により、S3 だけでなく、より高価な AWS EBS ストレージのコスト削減 も可能です。
また、SnapMirror® を使用した BlueXP レプリケーションにより、AWS リージョン間、オンプレミス環境、さらには異なるクラウド間でも、データを簡単かつ効率的に移動できます。
Cloud Volumes ONTAP がどのようにストレージ階層化を支援できるかについては、Cloud Volumes ONTAP Storage Tiering の導入事例 をご覧ください。
よくある質問(FAQ)
S3 バケットで Intelligent-Tiering を有効にする方法は?
S3 バケット一覧から対象のバケットを選択し、「Properties」→「S3 Intelligent-Tiering Configurations」→「Create」 をクリックします。設定の詳細については、AWS 公式ドキュメント を参照してください。
S3 Intelligent-Tiering は高コストですか?
S3 Intelligent-Tiering は初期コストが高くなる場合もありますが、アクセスパターンに基づいて 最もコスト効率の高いストレージ階層へ自動的にデータを移動 するため、長期的には組織全体のストレージコスト削減につながります。また、データ損失や破損に対する保護機能も強化されており、結果としてコストリスクの低減にも貢献します。