S3 Intelligent-Tiering 的存档即时访问层
分享该页面

Sudip Sengupta
Amazon Web Services (AWS) 为用户提供了许多选择,帮助他们找到完美的存储计划以优化成本和性能。最受欢迎的 S3 存储 类别之一是 S3 Intelligent-Tiering,自推出以来已帮助客户节省了 7.5 亿美元的存储成本。
S3 Intelligent-Tiering 可根据访问频率在不同存储层之间移动对象,从而优化存储成本。借助 AWS 最近推出的 Archive Instant Access 层,Intelligent-Tiering 现在可以自动存档数据以获得成本效益,同时提供亚毫秒级的检索访问。
在本文中,我们将了解 S3 Intelligent-Tiering 的 Archive Instant Access 层、其优势以及各种用例。
- 什么是 S3 中的智能分层?
- S3 Intelligent-Tiering Archive Instant Access 使用案例
- 如何启用 S3 智能分层
- 借助 BlueXP Cloud Volumes ONTAP 扩展 S3 Intelligent-Tiering 的优势
- 常见问题解答
什么是 S3 中的智能分层?
Amazon S3 Intelligent-Tiering 是一种基于云的对象存储类,可自动将对象归档到经济高效的存储层,以获得最大收益。凭借其智能算法,Intelligent-Tiering 可自动帮助优化存储成本,而不会牺牲性能或可用性。虽然存储类非常适合具有未知或不断变化的数据使用模式的数据,例如应用程序日志、媒体文件和传感器数据,但也可用于不需要尽可能低延迟的频繁访问的数据,例如备份和灾难恢复文件。
S3 Intelligent-Tiering 持续监控您的数据使用情况,并根据其访问模式在三个层级(热、温、冷)之间自动移动数据。热层级针对频繁访问的数据进行了优化,而温层级和冷层级则针对不常访问和很少访问的数据进行了设计。作为其主要优势之一,您只需为所消耗的存储付费,每月只需支付少量监控和自动化费用。
归档即时访问层的工作原理
存档即时访问 (AIA) 存储层为不常访问的数据提供快速检索时间,同时仍然提供云中存储的成本效益。与不频繁访问 (IA) 层相比,存档即时访问层使客户能够在不影响可用性或耐用性的情况下存档数据,知道他们可以立即检索所需的数据,而无需首先从较低的层恢复数据。
AIA 层对 S3 Intelligent-Tiering 类中的所有存储对象自动启用,其中 IA 层中的任何数据对象在 90 天内未访问将自动移动到 AIA 层。存储层还提供灵活性,可以根据需要将数据转换回 Standard 或 Bulk 存储层,而无需前期投资。
S3 Intelligent Tiering Archive Instant Access Tier 的优势
使用 S3 Intelligent-Tiering AIA 层的好处包括:
无需检索费用
虽然 Amazon S3 为归档层的数据出口付费,但您只需为所使用的数据付费。因此,在 AIA 层中存档的数据的重建或检索不会产生任何费用。这使其成为不常访问的数据的理想存储解决方案,这些数据仍然需要快速访问,而不会产生额外费用。
无最小存储持续时间
S3 Intelligent-Tiering AIA 层没有最小存储持续时间。您可以根据需要将对象存储在此层中的短期或长期,而无需担心任何最小值。这使其非常适合存储您可能不需要立即访问但仍希望保留以供将来使用的数据。您只需为使用的存储付费,因此只需存储将来需要的数据,即可将成本降至最低。
零运营开销
支持 S3 Intelligent-Tiering 的算法使用机器学习来监控访问模式,并就确定每个对象的最佳存储层做出实时决策。这意味着您不再需要担心在存储层之间手动移动对象或为不必要的存储付费。这与需要管理员输入和定期调整以保持最佳性能和成本效益的其他存储解决方案形成鲜明对比。
此外,AIA 层通过减少在检索之前跨层移动对象所涉及的工作量,提供对存档数据的即时访问。
低延迟和高吞吐量
AIA 层依赖于 S3 的基础技术,包括数据本地化、多个可用区、优化文件系统和高效缓存机制,以减少延迟。此设计模式使存储层能够提供亚毫秒级的检索,即使对于很少访问的数据也是如此。
此外,存储层还使用硬盘驱动器 (HDD) 和固态驱动器 (SSD) 的最佳组合来实现高吞吐量。这使其非常适合依赖高性能存储的工作负载,例如视频流或大数据分析。
S3 Intelligent-Tiering Archive Instant Access 使用案例
对于不经常访问但仍需要在需要时快速可用的数据,Amazon S3 的 Intelligent-Tiering AIA 层最有意义。这包括备份、日志文件和媒体文件等数据。与标准存储类相比,存档层的每 GB 价格更低,因此对于长期存储而言更具成本效益。而且,由于它仍然在 S3 中,您可以利用使用 S3 带来的所有好处,例如安全性和耐用性。
AIA 等级的一些适当用例包括:
不经常访问的存档存储
AIA 层的一个常见用例是存储不经常访问的数据。存储和检索的低成本使该层成为存档数据的理想选择,因为它可以长期存储而不会产生高成本。此外,该层的高持久性意味着即使很少访问数据,数据也将是安全且可访问的。
快速访问存储层
AIA 层的另一个常见用例是存储在需要时可以快速访问的数据。对此类数据使用此层的主要好处是其快速访问时间。这意味着用户可以访问他们需要的数据,而无需等待从较慢的存储形式中检索数据。此外,该层的高持久性意味着即使频繁访问数据,数据也将是安全且可访问的。
适用于不可预测的访问模式
AIA 层非常适合访问模式随时间变化不可预测的存储对象。例如,在音乐唱片收藏和流媒体应用程序中,用户经常访问最近上传的音乐。随着记录的老化,流媒体趋势逐渐减弱。经过几个月的无访问后,S3 的智能分层可以将音频文件移动到 AIA 层。艺术家人气的突然飙升可能会导致对其旧音乐的兴趣日益浓厚,然后可以立即检索其数据以通过 AIA 层进行流式传输,或者可以根据访问模式迁移到频繁访问层。
如何启用 S3 Intelligent Tiering
要开始使用 Intelligent-Tiering,首先需要创建一个新的存储类。这可以通过使用 S3 Console、AWS CLI 或 PUT API 对象来完成。创建存储类后,您可以使用简单的 API 调用将数据移动到其中。
注意:S3 Intelligent-Tiering 现在会自动将 IA 层中 90 天内未访问的任何对象分层到 AIA 层。为了针对存储桶的各个对象手动配置规则,您可以按照以下步骤操作。
使用 S3 Console
在存储桶的对象级别应用分层策略之前,请导航到 S3 控制台并选择要启用 Intelligent-Tiering 的存储桶。然后,选择管理选项卡并单击 Intelligent-Tiering。从那里,您可以通过检查是否启用了自动或手动模式来确认。在自动模式下,S3 将根据使用模式自动在层之间移动对象。使用手动模式允许您指定对象应存储在哪个层中。
让我们假设,您打算对现有存储桶的单个对象应用分层规则。要实现此目的,请按照以下工作流程进行操作:
- Sign in 到 AWS S3 控制台,然后从 S3 存储桶列表中选择目标存储桶。
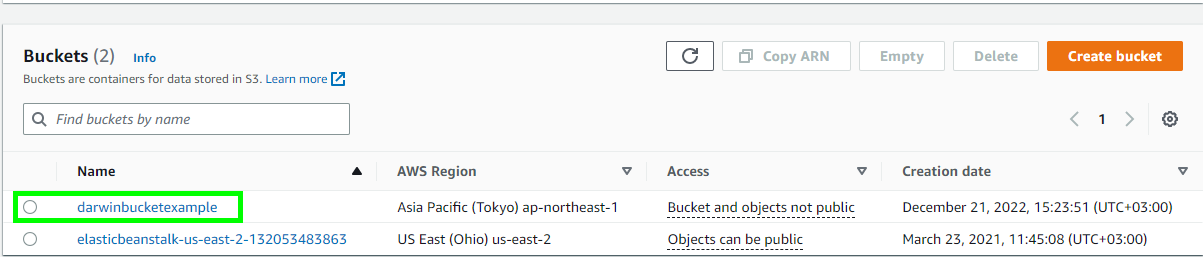
- 选择 Properties 选项卡。
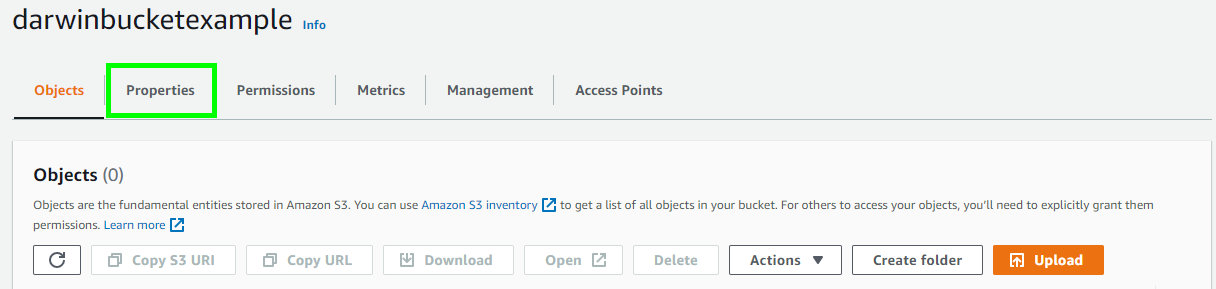
- 转到 S3 Intelligent-Tiering Archive configurations 部分,然后选择"Create configuration"按钮。

- 您现在将进入存档配置设置部分。输入配置的名称,并决定是将配置应用于整个存储桶还是应用于单个对象。在我们的示例中,我们选择将规则应用于单个对象。
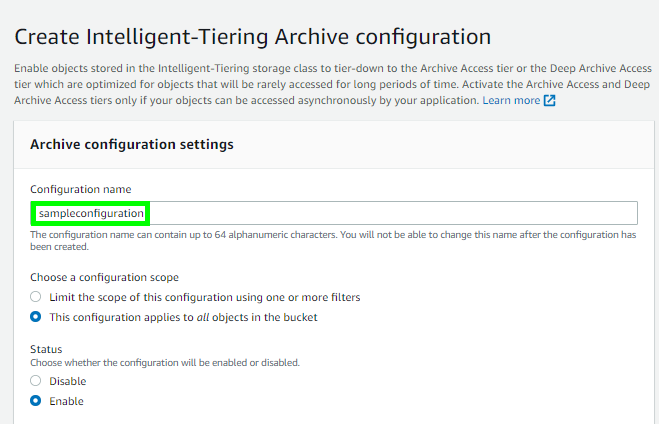
- 单击Create以确认配置,该配置在成功创建后显示在 S3 控制台中。

使用 Amazon CLI
您还可以使用 AWS CLI 命令来管理 S3 Intelligent 层的配置。
这样做的典型方法是使用 put-bucket-intelligent-tiering-configuration 命令,并将配置指定为 JSON 文件以启用不同的分层选项。以下命令将 AIA 配置分配给 darwinbucketexample 存储桶。
$ put-bucket-intelligent-tiering-configuration
{ "Id": "darwinbucketexample", "Filter": { "Prefix": "filter-criteria1", "Tag": { "Key": "object-tag-key1", "Value": "object-tag1" }, "And": { "Prefix": "filter-criteria2", "Tags": [ { "Key": "object-tag-key2", "Value": "object-tag2" } ...] } }, "Status": "Disabled" "Tierings": [ { "Days": integer, "AccessTier": "ARCHIVE_ACCESS"\|"DEEP_ARCHIVE_ACCESS" } ...]}
使用 PUT API 操作
您还可以使用 PUT API 对象应用有关如何将数据移动到 S3 Intelligent-Tiering 并随后存档的规则。
例如,要将 darwinbucketexample 存储桶移动到 Intelligent-Tiering,您必须将 INTELLIGENT_TIERING 作为存储类包含在 x-amz-storage-class 标头下。
PUT /darwin-image.jpg HTTP/1.1Host: darwinbucketexample.s3..amazonaws.com (http://amazonaws.com/)Date: Thu, 22 Dec 2021 15:50:33 GMTAuthorization: authorization stringContent-Type: image/jpegContent-Length: 22452Expect: 100-continuex-amz-storage-class: INTELLIGENT_TIERING
完成后,您可以使用 PutBucketIntelligentTieringConfiguration API 操作为特定存储桶或存储桶对象配置 Intelligent-Tiering 的存档规则。
借助 BlueXP Cloud Volumes ONTAP 扩展 S3 Intelligent-Tiering 的优势
虽然 S3 Intelligent-Tiering 为 S3 用户添加了急需的功能,NetApp BlueXP Cloud Volumes ONTAP 可以将其进一步作为 AWS 的数据管理层。
Cloud Volumes ONTAP 数据分层可以自动将不常用的 EBS 存储数据分层到更具成本效益的 S3 Intelligent-Tiering,并在需要时自动将其移回。在 AWS 上本机无法在对象和块存储之间进行分层。
但这并不是优势的终点。Cloud Volumes ONTAP 为 AWS 用户提供更高级别的数据保护,使用更具成本效益和空间效率的NetApp Snapshot 技术和Cloud Backup。内置存储效率(包括重复数据删除、压缩和精简配置)可以降低整体存储成本,不仅适用于 S3,还适用于更昂贵的AWS EBS 存储。借助 BlueXP replication 和 SnapMirror®,您可以在 AWS 区域、本地部署甚至不同云之间轻松高效地移动数据。
详细了解 Cloud Volumes ONTAP 如何通过这些 Cloud Volumes ONTAP 存储分层案例研究提供帮助。
常见问题解答
如何在 S3 存储桶上启用 Intelligent-Tiering?
要在 S3 存储桶上启用 Intelligent-Tiering,首先从存储桶列表中选择存储桶的名称。在存储桶的页面上,选择 Properties,滚动到 S3 Intelligent-Tiering Configurations 部分,然后单击 Create。有关 S3 存储桶的智能层配置设置的其他详细信息,请参阅 AWS 官方文档。
S3 Intelligent-Tiering 是否昂贵?
虽然 S3 Intelligent-Tiering 可能会产生更高的初始成本,但从长远来看,它最终可以为组织节省资金。借助 S3 Intelligent-Tiering,数据将自动移动到最具成本效益的存储层,从而为他们节省存储成本。这通常通过根据访问模式将数据自动存储在最合适的存储类中来实现,使其成为不经常访问的数据的理想选择。此外,S3 Intelligent-Tiering 可提供额外的保护,防止数据丢失和损坏,从而进一步降低成本意外情况。