AWS 可用区、区域和安置组说明
分享该页面

Aviv Degani
业务组织使用的应用程序需要不同级别的可用性和不同的 SLA 目标。在出现故障时,应用程序的关键性或要求程度与其在吞吐量、响应速度和恢复时间方面的要求成正比。在形成AWS 高可用性最佳实践时,同样的考虑因素也适用。
根据部署的具体要求,结合放置组在 AWS 可用区中分布计算和存储是解决 AWS 高可用性这一挑战的一种方法。这些选项的优化组合以及 Cloud Volumes ONTAP HA 部署可以满足每个层提出的要求。
在本文中,我们将回顾单个和多个可用区以及放置组的这些 AWS 高可用性最佳实践和使用案例。我们还将了解 Cloud Volumes ONTAP HA 作为存储级别的解决方案可以带来的额外好处。
在本文中,您将了解:
什么是 AWS 区域和可用区?
可用区是每个 AWS 区域内的高可用性数据中心。一个区域表示一个单独的地理区域。每个可用区都有独立的电源、散热和网络。当整个可用区出现故障时,AWS 能够将工作负载故障转移到同一区域中的其他区域之一,这种功能称为"多 AZ"冗余。
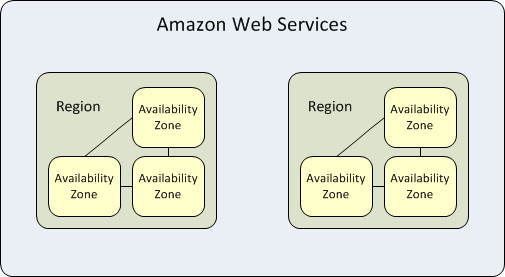
每个 AWS 区域都是隔离的,独立于其他区域运行,但每个区域内的可用区通过低延迟链路连接,以提供复制和容错。如果您将所有数据和实例托管在受故障影响的单个可用区中,则它们将不可用。
这种隔离的目的是为具有高数据主权和合规性要求的工作负载提供服务,这些要求不允许用户数据传输到特定地理区域之外。这些类型的工作负载受益于 AWS 可用区的结构,具有低延迟和完全与其他区域分离的特点。
查看 AWS 全球基础架构中可用区域的完整列表。
AWS 区域与可用区
在不同区域运行工作负载与在同一区域内的不同可用区运行工作负载之间存在两个关键的操作差异。
地理分布
AWS 区域和可用区的地理分布也在应用程序的性能和可靠性方面发挥着重要作用。
如果您跨单个区域中的多个可用区部署应用程序,则可以实现一定级别的高可用性和容错,但低于在不同区域部署所提供的水平。如果一个可用区出现故障,您的应用程序可以继续在另一个可用区中运行,而不会出现任何中断。但是,如果整个区域失败,您的应用程序将失败。
另一方面,在多个区域部署应用程序意味着即使整个区域失败(非常不可能的情况),您的应用程序也可以继续运行。跨区域部署可提供额外好处,例如降低全球用户的延迟和更快的灾难恢复。
计算和数据传输成本
在成本方面,AWS 资源的位置可能会产生显著影响。由于当地需求、基础设施成本和当地税法等因素,每个 AWS 区域的服务定价都不同。例如,在亚太(孟买)地区运行 EC2 实例的成本可能高于在美国东部(弗吉尼亚北部)地区运行相同实例的成本。但是,跨同一区域的不同 AZ 运行工作负载的成本通常是相同的。
此外,数据传输成本可能会有所不同,具体取决于数据是在同一区域内传输、在不同区域之间传输,还是在区域与公共互联网之间传输。与跨区域或向公共互联网传输数据相比,在同一区域内或同一区域内的可用区之间传输数据通常更便宜。
选择 AWS 区域时需要考虑的参数
在选择 AWS 区域和 AZ 来托管和部署应用程序之前,一些参数是需要考虑的关键,以便获得最佳结果。
以下列表提供了需要考虑的最重要参数:
参数 #1:延迟和接近度—选择最接近的区域以实现低延迟。
与服务器的快速连接确保了在快速加载和传输时间方面的更佳性能,从而带来更好的整体用户体验。您可以通过选择最接近大多数客户群的 AWS 区域来实现这一目标。云和最终用户之间的距离越短,延迟越低。例如,如果您的大多数客户都在北美地区访问您的应用程序,则选择美国或加拿大地区的可用区将产生最佳结果。
AWS 服务的价格因地区而异,具体取决于物理基础设施成本和税收等因素。不同地区之间的差异可能高达数百美元,因此选择正确的区域是减少不必要成本的关键。您可以使用官方价格计算器查看哪个地区最适合您的需求。还可以查看 NetApp 的AWS 计算器,它可让您计算总拥有成本,包括存储服务成本。
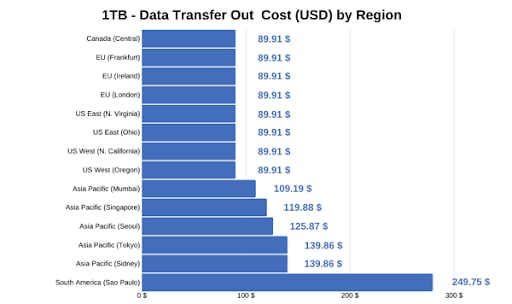
参数 #2:成本—选择提供最佳性价比的区域。
下表显示了每个地区 1TB 数据传输的各种价格,供参考。
参数 #3:监管合规和安全
—保护公司资产每个国家或联盟都有一套不同的合规规范和规则来保护用户数据。某些地区可能会禁止其地区与其他地区之间的转移。违反此类合规法规可能会导致诉讼,并对贵组织造成严重的财务和声誉损害。此外,如果您在全球范围内提供服务,则应考虑使用多个 AWS 区域和可用区,为客户提供最快、最可靠的服务。
参数 #4:服务级别协议(SLA)—正确的参数以获得更好的服务。
AWS 服务根据其独特的可用性和参数提供不同的 SLA。当您根据 AWS 设计部署应用程序时,AWS 将最好地遵守 SLA。在选择区域和 AZ 时,请考虑所有其他参数以及您的要求,以确保它们为托管和部署您的应用程序提供最佳解决方案。
什么是多 AZ 部署?
对于关键任务工作负载,例如企业数据库—无论是托管在 Amazon EC2 实例上还是托管在 Amazon 本地数据库服务(例如 Amazon RDS)上—多 AZ 分发模型可为您提供高可用性,以防整个可用区发生重大故障。
即使承受不起中等停机时间的关键生产应用程序也能从此模型中获益,并且必须将这种类型的一般故障视为真正的可能性。这同样适用于此应用程序可能包含的上层。如果应用程序的 Web 服务全部托管在一个 AZ 中,则如果 Web 层仅托管在一个 AZ 中,将底层数据库托管在 HA 多 AZ 配置中将无济于事。
从这个高可用性的角度来看,在单个 AZ 部署中,如果 AZ 出现故障,一切都会下降,恢复时间目标会更高。更不用说中间将发生的数据丢失。
多 AZ 部署的其他重要好处包括:
- 备份期间不会发生 I/O 延迟,因为备份是从备用实例中获取的。
- 为维护目的应用修补程序或执行升级时不会中断 I/O。
- 使用负载平衡时提高响应速度。如果一个 AZ 受到限制,则其他区域中的实例可以消化流量。
当然,并非所有应用用例都需要多 AZ 部署。临时测试、开发部署或任何非关键用例都可以托管在单个 AZ 中,并避免运行多 AZ 带来的额外成本。甚至还有一些更适合单 AZ 模型的高密度、极低延迟用例。
AWS 放置组
简而言之,放置组是 AWS 提供的一种配置选项,它允许您以某种方式跨越这些实例所驻留的底层硬件放置一组相互依赖的实例。这些实例可以紧密放置、分布在不同的机架上或分布在不同的可用区中。让我们更深入地了解您可以选择的每种放置组类型以及最适合每个分发选项的工作负载类型:
1.集群放置组
集群放置组配置允许您将相互关联的实例组放在一起,以实现最佳吞吐量和尽可能低的延迟结果。此选项仅允许您将实例打包在同一可用区内,无论是在同一 VPC 中还是在对等 VPC 之间。
集群放置组的优势在于,这些实例之间的通信不限于 5 Gbps 的单流流量,而是 10 Gbps 单流(点对点)流量和总计 25 Gbps 的聚合流量。HPC(高性能计算)网络绑定应用程序是此部署模型的最佳用例。计算工程、实时事件流、基因组学测序、天文学模型和地球气候计算模型是云中此类分组的用例示例。
2.分区放置组
使用分区放置组,您可以将实例分组在构成放置组的单独逻辑分区中。这样做的想法是将每个逻辑分区构建在单独的硬件机架之上,以避免常见的硬件故障。如果一个机架出现故障,它只会影响驻留在此逻辑分区上的实例。每个逻辑分区由多个实例组成。分区放置组选项允许您将这些分区放置在单个 AZ 内或同一区域内的多 AZ 设置中。
那么,哪种类型的负载最适合此模型?需要分发和复制的大数据存储就是很好的例子。HDFS 或 Cassandra 等大型文件系统也非常适合。分区放置组允许您查看哪些实例放置到哪些分区中,以便可以制作 Hadoop 或 Cassandra 拓扑感知并正确配置数据复制。任何需要大数据分析、数据报告或大规模索引的用例也非常适合分区放置组。
3.分散放置组
使用分散放置组,每个实例在单独的物理硬件机架上运行。因此,如果您部署五个实例并将其放入此类型的放置组中,则这五个实例中的每一个实例都将驻留在具有其自己的网络访问和电源的不同机架上,无论是在单个 AZ 还是在多 AZ 架构中。
分散放置组设置可能类似于分区放置组,但主要区别在于分区放置组由每个分区上的多个实例组成,而分散组只是通过不同机架或 AZ 分散的单个实例。
建议将此模型用于业务的少量关键实例。您可能在此处运行少量SQL 数据库实例或您的 Web 应用程序层。此设置是冗余的理想用例,因为对分区和集群放置组提供的强大计算能力的要求较低。
Cloud Volumes ONTAP HA for AWS
Cloud Volumes ONTAP HA 配置提供 AWS 高可用性。在 Amazon EC2 计算实例的双节点上运行并将所有数据存储在底层Amazon EBS 存储中,操作可以防止在故障中发生任何数据丢失,并在 60 秒内恢复。
在此 Cloud Volumes ONTAP 对中,在两个节点之间镜像所有数据,无论是在主动-主动配置中,两个节点都为客户端提供服务,还是在主动-被动配置中,其中一个节点是备用节点。在这两种情况下,每次写入新数据时都会同步镜像数据。此配置也可以部署在单个 AZ 场景或多个 AZ 场景中:
- 单个 AZ:两个 Cloud Volumes ONTAP 节点位于同一个可用区。NetApp Cloud Manager 会使用分散放置组配置自动部署两个节点,以避免常见的计算故障。
- 多 AZ:每个 Cloud Volumes ONTAP 节点驻留在不同的可用区中,再次消除了 AZ 作为单点故障,这不是本机 Amazon EBS 存储复制提供的功能。使用此类型的高可用性配置,您需要使用浮动 IP 地址设置 AWS Transit Gateway,以便故障转移正常工作并提供永久 NAS 或任何数据访问。
Cloud Volumes ONTAP HA 需要三个 Amazon EC2 实例才能正常工作:两个主节点负责所有存储工作,一个小型调解器 t2.micro 实例负责调节和管理自动故障转移和故障恢复相关任务。RPO(恢复点目标)为零,您的数据始终保持一致,因为它是同步镜像的,并且您的 RTO(恢复时间目标)为 60 秒或更短,以便在故障切换到另一个节点时数据再次可用。
AWS 还具有其他本机存储层冗余功能,例如 Amazon EBS。如前所述,Amazon EBS 仅在单个可用区上的服务器内进行复制,如果您仅使用 Amazon EBS 在存储级别提供冗余,则需要获取 Amazon S3 快照并将其传输到其他可用区,这也会产生额外费用。其他 AWS 本机高可用性功能(如Amazon EFS)仅通过 NFS 导出存储的数据,目前不支持 Windows 实例。
结论
本文中提供的关于 AWS 高可用性最佳实践的所有信息使我们得出三个主要结论:
- 只要存在多 AZ 配置,就会获得额外的可靠性点,因为整个可用区本身被排除为单点故障。
- 不同的工作负载有不同的要求,这些要求可以更适合单 AZ 部署或多 AZ 部署。
- 无论您是在单 AZ 模式还是多 AZ 模式下部署,只要需要集中式存储,Cloud Volumes ONTAP HA 都是一种在存储层提供冗余和快速恢复的解决方案。与在原始 Amazon EBS 存储上运行相比,其价格更低或相当。
您的业务连续性非常重要。Cloud Volumes ONTAP 让您能够确保它。