Thin Cloning: acelera el desarrollo y reduce costes con FSx para ONTAP
Compartir esta página

Yifat Perry
Sigue leyendo para saber más o usa los enlaces siguientes:
- Por qué es importante copiar tu conjunto de datos (y qué lo dificulta)
- Existe una forma más eficiente de clonar datos con FSx para ONTAP
- Cómo un importante proveedor de juegos como servicio acelera el desarrollo con FSx para ONTAP
- En resumen: desarrollo más rápido, menores costes
Por qué es importante copiar tu conjunto de datos (y qué lo dificulta)
Todos sabemos que los datos son uno de los activos más importantes de una organización. Pero la diferencia radica en cómo se utilizan. Dada su importancia, no es algo que quieras andar manipulando. Para usar tus datos correctamente, necesitas una "copia de oro", esto es, una versión idéntica de tu conjunto de datos que sirva como entorno de pruebas y que puedas recrear repetidamente. Esta copia maestra mantiene el conjunto de datos principal a salvo de tus pruebas y te permite someter la copia a pruebas sin afectar la producción.
Las dos áreas más importantes donde dichas copias entran en juego son el flujo de desarrollo y la creación de nuevos entornos.
En lo que respecta a DevTest, una métrica importante es cuántas pruebas puedes ejecutar en una base de código por hora. Cuantas más pruebas se ejecuten, más ágil será y más rápido progresará la base de código. Algunas pruebas requieren cientos de ejecuciones, lo que implica cientos de copias.
Las copias de datos también se utilizan mucho en las pruebas de entornos de recuperación de desastres (DR), lo que conlleva usar copias de datos para restaurar los servicios de la aplicación fuera de la ubicación principal de datos. Otros casos de uso populares para las copias de datos incluyen la actualización de bases de datos, el análisis exploratorio de datos, la computación de alto rendimiento para medios y entretenimiento (M&E), la analítica y la IA.
Sin embargo, crear copias para estos fines puede ser un desafío por varias razones.
- Copiar datos lleva tiempo. Para crear una versión de los datos que puedas probar de forma segura, deberás crear una copia de la copia maestra. Desde siempre, este proceso conlleva mucho tiempo. Dependiendo del tamaño de tu conjunto de datos, crear las copias necesarias puede consumir la mayor parte del tiempo de ejecución de la prueba, y esto limita el número de pruebas por hora, lo que a su vez retrasa su lanzamiento.
- Un rápido aumento del uso y los costes de almacenamiento. Dado que las copias de datos duplican completamente el conjunto de datos original, cada copia duplica el consumo de almacenamiento y aumenta tus recursos de computación y red. El proceso DevTest puede requerir la creación de muchas (a veces cientos) de estas copias, lo que dispara los costes. Además, los desarrolladores y administradores dedicarán mucho tiempo y energía administrativa a gestionar estas copias.
Retraso en el tiempo de comercialización. Impulsar nuevas versiones es fundamental para que las aplicaciones se mantengan ágiles y competitivas. No podrás lograrlo si tu calendario de lanzamiento se ve obstaculizado por mecanismos de copia excesivamente largos y complejos.Problemas de rendimiento. Acceder y actualizar copias de datos en contextos multiusuario o multiaplicación podría resultar de recursos, lo que a su vez genera problemas de rendimiento.Se requiere una planificación meticulosa para garantizar que los clones sean consistentes y estén actualizados, lo que aumenta la sobrecarga operativa.Sobrecarga operativa. Gestionar múltiples copias de datos puede ser complicado y dar lugar a errores. Requiere una planificación meticulosa para garantizar que los clones sean consistentes y estén actualizados, lo que incrementa la sobrecarga operativa.
Los desafíos de trabajar con copias de datos son considerables, pero NetApp y AWS se han asociado para ofrecer una solución para copias de clones finos grabables: Amazon FSx para NetApp ONTAP.
Existe una forma más eficiente de clonar datos con FSx para ONTAP
Amazon FSx para NetApp ONTAP tiene una capacidad de clonación de datos integrada que se proporciona mediante la tecnología NetApp® FlexClone®. Esta capacidad le permite crear copias locales instantáneas de sus volúmenes de datos en un momento dado: copias con capacidad de escritura que consumen un espacio de almacenamiento mínimo.
Estos clones "delgados" agilizan y reducen considerablemente el coste de crear entornos de prueba, actualizar bases de datos y mucho más.
Cómo funciona la clonación de FSx para ONTAP
FSx para ONTAP utiliza la tecnología FlexClone para crear copias con capacidad de escritura que ahorran espacio. Así funciona:
- Puede crear al instante copias locales con capacidad de escritura de volúmenes, LUN y archivos. Las copias instantáneas de volúmenes de datos creadas por FSx para ONTAP aprovechan una capa virtual sobre una copia Snapshot™ de NetApp existente. Esa copia Snapshot actúa como una copia maestra y requiere muy pocos metadatos. Las copias clonadas se crean independientemente de la copia maestra, lo que hace que el proceso de clonación sea extremadamente eficiente en términos de espacio.
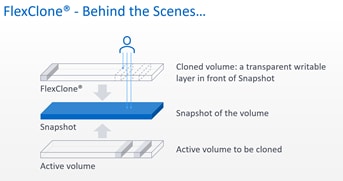
- Los clones se actualizan independientemente de los volúmenes principales. Una copia clonada comparte los mismos bloques que su principal, y solo se consume espacio de almacenamiento adicional cuando se produce un cambio en los datos. El cambio de datos se actualiza en incrementos de bloques de 4K.
Por lo tanto, los clones no afectan el rendimiento de las aplicaciones que utilizan los volúmenes de datos de producción. Si es necesario, también puede separar los clones de su copia maestra y usarlos de forma independiente; sin embargo, esto requeriría espacio adicional en disco.
Al clonar volúmenes de recuperación ante desastres correspondientes a su entorno de producción, para pruebas u otros fines, la función SnapMirror® funciona continuamente para replicar los datos en los volúmenes principales de los clones mientras su equipo de DevTest trabaja en ellos.
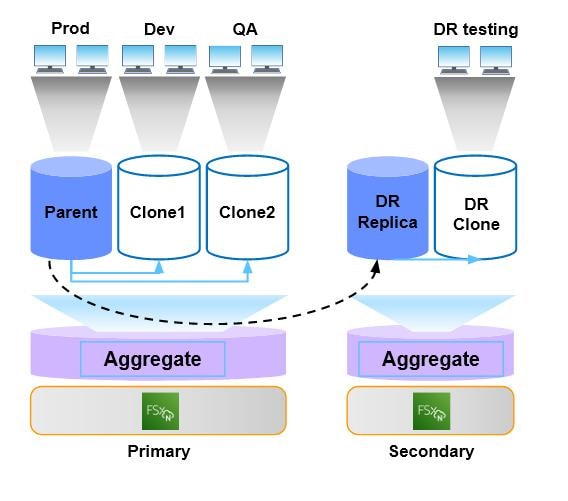
- Los clones son eficientes en cuanto al espacio, lo que reduce los costos. Considere el ejemplo de DevTest para una base de datos de producción de 100 GB. Normalmente, esto requiere un espejo completo y varias copias para desarrolladores y evaluadores. Si asumimos que se requieren tres de cada tipo, el almacenamiento total requerido es de 800 GB, incluyendo el de la base de datos de producción.
Incluso si se mantiene una copia espejo completa de los datos para evitar afectar el almacenamiento de producción, el uso de FlexClone para copias de DevTest reduce el consumo de almacenamiento a 260 GB. Esto reduce la cantidad total de almacenamiento requerida en un 67 % y reduce los costos proporcionalmente. Obtenga más información sobre cómo determinar el espacio utilizado por un volumen FlexClone. - Los clones tienen una baja sobrecarga de rendimiento. Dado que los clones tienen un impacto prácticamente nulo en el almacenamiento, no tiene que preocuparse por actualizarlos frecuentemente con datos de producción actualizados. Esto significa que siempre podrá realizar pruebas con datos actualizados, en lugar de datos obsoletos.
Los clones también le permiten realizar pruebas sin afectar el entorno de producción. Una vez finalizadas las pruebas, simplemente elimine el clon y cree una nueva imagen de clonación limpia en cuestión de segundos.
También puede usar API para automatizar el proceso de clonación e integrarlo con su canalización de CI/CD (integración e implementación continuas). Este enfoque evita los desafíos de la clonación de DevTest mencionados anteriormente. - Si puede realizar pruebas más rápido, estará lanzando compilaciones más rápido.
Cómo se benefician los canales de desarrollo de la clonación de datos con FSx para ONTAP
Veamos algunos de los logros que puede obtener con la clonación de datos de FSx para ONTAP.

- Tiempo de comercialización más rápido con entornos de desarrollo creados al instante. Con la función FlexClone, las copias de los entornos de producción se crean instantáneamente. Los desarrolladores que usan FlexClone dedican menos tiempo a esperar las copias y más tiempo a trabajar, ya que los clones se crean y se limpian rápidamente. Esto, a su vez, genera mayor agilidad, mayor productividad del equipo de desarrollo y una comercialización más rápida.
- Ahorro de costos. Dado que los clones delgados consumen un espacio de almacenamiento mínimo, no generan muchos costos adicionales en AWS.
- Actualización rápida del entorno. Dado que FSx for ONTAP crea clones de datos instantáneamente, puede actualizar el entorno de desarrollo y pruebas con los datos del entorno de producción siempre que sea necesario. Esta velocidad de actualización le permite realizar pruebas con mayor frecuencia y con los datos más actualizados.
- Pruebas de impacto cero. FlexClone le permite realizar pruebas sin comprometer su entorno de producción ni su conjunto de datos principal. Una vez finalizadas las pruebas, puede simplemente eliminar el clon y generar uno nuevo en segundos. Esta capacidad reduce los gastos generales y acelera el proceso de desarrollo.
Cómo un importante proveedor de juegos como servicio acelera el desarrollo usando FSx para la clonación de ONTAP
Este desarrollador de juegos y proveedor de juegos como servicio publica algunos de los títulos más populares de la actualidad, con cientos de millones de jugadores en todo el mundo conectados a través de redes internas. La migración a FSx para ONTAP ha tenido un impacto significativo en cómo esta empresa logra todo esto.
La empresa de juegos buscaba acelerar el ciclo de desarrollo en sus operaciones de compilación en AWS. Dado que el producto del juego está en línea, requiere lanzamientos cortos constantes. AWS ofreció acceso a mayor potencia de procesamiento y escalabilidad, duplicando el número de compilaciones diarias. Con FSx para ONTAP como capa de almacenamiento, la empresa logró aún más:
- Redujo el tiempo de transferencia del código fuente a nuevas instancias de horas a minutos. Anteriormente, el trabajo en el código debía detenerse mientras se creaban copias de datos, lo que ralentizaba todo el proceso de CI/CD. Con la clonación fina con FSx para ONTAP, se pudieron crear nuevas copias instantáneamente y luego compartirlas fácilmente.
- Redujo los costos de almacenamiento para las pruebas masivas de código base. Hay cientos de instancias ejecutando pruebas paralelas en desarrollo. La tecnología FlexClone crea clones de datos con costo de capacidad cero en lugar de copiar volúmenes completos de datos para cada copia de prueba y almacenarlos a costo completo. El ahorro resultante es significativo.
- Eliminó el potencial de tiempo de inactividad. Con la alta disponibilidad de múltiples zonas de disponibilidad (multi-AZ) integrada en FSx para ONTAP, los datos se encuentran en dos nodos que se mantienen sincronizados en dos AZ separadas. Incluso si se produce una interrupción en una zona de disponibilidad (AZ), el proceso de compilación puede continuar sin interrupciones, ya que los desarrolladores pueden acceder a los datos almacenados en el nodo de FSx para ONTAP en la zona de disponibilidad (AZ) no afectada.
En resumen: Desarrollo más rápido, menores costos
Las exigencias del ciclo de desarrollo en la capa de almacenamiento pueden generar altos costos y retrasos en la programación. Con la clonación fina de Amazon FSx para NetApp ONTAP, no solo obtiene clones instantáneos con rendimiento neutro, sino que también evita pagar por capacidad de almacenamiento adicional al crear copias.
No permita que sus datos lo ralenticen. Permita que la capacidad de clonación fina de FSx para ONTAP le ahorre tiempo y dinero.
