Zonas de disponibilidad, regiones y grupos de colocación de AWS explicados
Compartir esta página

Aviv Degani
Las organizaciones empresariales utilizan aplicaciones que requieren diferentes niveles de disponibilidad y diferentes objetivos de SLA. Qué tan crítica o exigente se considera una aplicación es proporcional a sus requisitos de rendimiento, capacidad de respuesta y tiempo de recuperación en caso de fallo. Las mismas consideraciones se aplican al formar mejores prácticas de alta disponibilidad de AWS.
Dependiendo de los requisitos específicos del despliegue, distribuir el cómputo y almacenamiento a través de las Zonas de Disponibilidad de AWS en combinación con Placement Groups es una forma de abordar este desafío en la alta disponibilidad de AWS. Una combinación optimizada de esas opciones, junto con un despliegue de Cloud Volumes ONTAP HA, puede cumplir con los requisitos presentados por cada capa.
En este artículo vamos a revisar estas mejores prácticas de alta disponibilidad de AWS y casos de uso para Zonas de Disponibilidad únicas y múltiples, y Placement Groups. También veremos los beneficios adicionales que Cloud Volumes ONTAP HA puede aportar como solución a nivel de almacenamiento.
En este artículo, aprenderás:
- ¿Qué son las Regiones y Zonas de Disponibilidad de AWS?
- Parámetros a Considerar al Elegir una Región de AWS
- ¿Qué es un Despliegue Multi-AZ?
- AWS Placement Groups
- Cloud Volumes ONTAP HA para AWS
¿Qué son las Regiones y Zonas de Disponibilidad de AWS?
Las zonas de disponibilidad son centros de datos altamente disponibles dentro de cada región de AWS. Una región representa un área geográfica separada. Cada zona de disponibilidad tiene energía, refrigeración y redes independientes. Cuando una zona de disponibilidad completa se cae, AWS puede hacer failover de las cargas de trabajo a una de las otras zonas en la misma región, una capacidad conocida como redundancia "Multi-AZ".
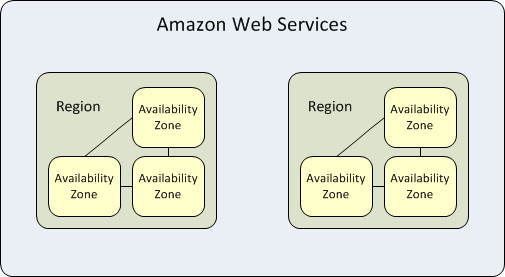
Cada región de AWS está aislada y opera independientemente de otras regiones, pero las zonas de disponibilidad dentro de cada región están conectadas a través de enlaces de baja latencia para proporcionar replicación de datos y tolerancia a fallos. Si alojas todos tus datos e instancias en una sola zona de disponibilidad, que se ve afectada por un fallo, no estarían disponibles.
El propósito de este aislamiento es servir cargas de trabajo con alta soberanía de datos y requisitos de cumplimiento que no permiten que los datos del usuario pasen fuera de una región geográfica específica. Estos tipos de cargas de trabajo se benefician de la estructura de las zonas de disponibilidad de AWS con baja latencia y separación completa de otras regiones.
Ve una lista completa de regiones disponibles dentro de la infraestructura global de AWS.
Regiones de AWS vs. Zonas de Disponibilidad
Hay dos diferencias operativas clave entre ejecutar tus cargas de trabajo en diferentes regiones vs. diferentes zonas de disponibilidad dentro de la misma región.
Distribución Geográfica
La distribución geográfica de las regiones y zonas de disponibilidad de AWS también juega un papel significativo en el rendimiento y confiabilidad de tus aplicaciones.
Si despliegas tu aplicación a través de múltiples zonas de disponibilidad en una sola región, puedes lograr cierto nivel de alta disponibilidad y tolerancia a fallos, pero menor que el proporcionado por desplegar en diferentes regiones. Si una zona de disponibilidad falla, tu aplicación puede continuar ejecutándose en otra zona de disponibilidad sin ninguna interrupción. Sin embargo, si toda la región falla, tu aplicación fallará.
Por otro lado, desplegar tu aplicación en múltiples regiones significa que incluso si una región completa falla (un escenario muy improbable), tu aplicación puede continuar funcionando. Desplegar a través de regiones proporciona beneficios adicionales como latencia reducida para tus usuarios globales y recuperación ante desastres más rápida.
Costo de Cómputo y Transferencia de Datos
Cuando se trata de costos, la ubicación de tus recursos de AWS puede tener un impacto significativo. Cada región de AWS tiene precios diferentes para los servicios debido a factores como la demanda local, costos de infraestructura y leyes fiscales locales. Por ejemplo, ejecutar una instancia EC2 en la región Asia Pacific (Mumbai) probablemente cueste más que ejecutar la misma instancia en la región US East (N. Virginia). Sin embargo, el costo de ejecutar cargas de trabajo a través de diferentes AZ en la misma región es generalmente el mismo.
Además, los costos de transferencia de datos pueden variar dependiendo de si los datos se transfieren dentro de la misma región, entre diferentes regiones, o entre regiones e internet público. Transferir datos dentro de la misma región o entre zonas de disponibilidad en la misma región es generalmente más barato comparado con transferir datos a través de regiones o a internet público.
Parámetros a Considerar al Elegir una Región de AWS
Algunos parámetros son clave a considerar antes de elegir una región y AZ de AWS para alojar y desplegar tu aplicación para obtener los mejores resultados.
La siguiente lista proporciona los parámetros más importantes a tomar en consideración:
Parámetro #1: latencia y proximidad—opta por la región más cercana para baja latencia.
Una conexión rápida al servidor asegura mejor rendimiento en términos de tiempos de carga y transferencia rápidos, lo que resulta en una mejor experiencia general del usuario. Puedes lograr esto eligiendo una región de AWS que esté más cerca de la mayoría de tu base de clientes. Mientras más corta sea la distancia entre la nube y el usuario final, menor será la latencia. Por ejemplo, si la mayoría de tus clientes acceden a tu aplicación dentro de la región de América del Norte, elegir una zona de disponibilidad dentro de las regiones de Estados Unidos o Canadá generará los mejores resultados.
Los precios de los servicios de AWS varían dependiendo de la región basándose en elementos como el costo de la infraestructura física e impuestos. La diferencia entre varias regiones puede ascender a cientos de dólares, por lo que elegir la correcta es clave para reducir costos innecesarios. Puedes usar la calculadora oficial de precios para ver qué región se adapta mejor a tus necesidades. También revisa la Calculadora de AWS de NetApp, que te permite calcular el TCO incluyendo el costo de los servicios de almacenamiento.
Parámetro #2: costo—elige una región que ofrezca la mejor relación precio-rendimiento.
A continuación hay una tabla de referencia que muestra los varios precios para cada región para una transferencia de datos de 1TB.
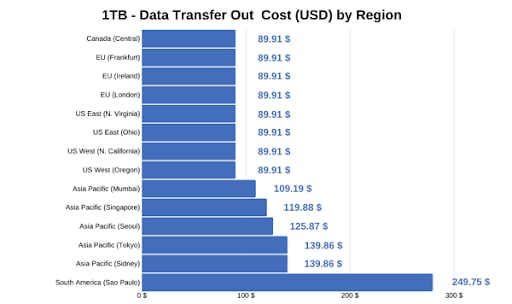
Parámetro #3: cumplimiento regulatorio y seguridad—protegiendo los activos de la empresa
Cada país o unión tiene un conjunto diferente de normas y reglas de cumplimiento para proteger los datos del usuario. Algunas regiones pueden prohibir la transferencia entre su región y otras regiones. Una violación de tales regulaciones de cumplimiento puede llevar a demandas y resultar en daño financiero y reputacional crítico para tu organización. Además, si ofreces servicios mundiales, deberías considerar usar múltiples regiones y zonas de disponibilidad de AWS para ofrecer el servicio más rápido y confiable a tus clientes.
Parámetro #4: acuerdos de Nivel de Servicio (SLA)—parámetros correctos para obtener mejor servicio.
Los servicios de AWS ofrecen diferentes SLA basados en su disponibilidad y parámetros únicos. AWS cumplirá mejor el SLA cuando despliegues la aplicación según el diseño de AWS. Toma todos los otros parámetros en consideración junto con tus requisitos al seleccionar una región y una AZ para asegurar que ofrezcan la mejor solución para alojar y desplegar tu aplicación.
¿Qué es un Despliegue Multi-AZ?
Cuando se trata de cargas de trabajo críticas para la misión, como bases de datos empresariales— ya sea alojadas en instancias Amazon EC2 o en servicios nativos de base de datos de Amazon (como Amazon RDS)—un modelo de distribución multi-AZ te da alta disponibilidad en caso de que ocurra un fallo mayor en una Zona de Disponibilidad completa.
Las aplicaciones de producción críticas que no pueden permitirse ni siquiera una cantidad moderada de tiempo de inactividad se benefician de este modelo y tienen que considerar este tipo de fallo general como una posibilidad real. Lo mismo aplica para los niveles superiores de los que esta aplicación puede estar compuesta. Si los servicios web de una aplicación están todos alojados en una AZ, tener las bases de datos subyacentes en una configuración HA multi-AZ no ayudará mucho si el nivel de aplicación está alojado en solo una AZ.
Desde esta perspectiva de alta disponibilidad, en un despliegue de AZ única, si la AZ se cae todo se cae y el Objetivo de Tiempo de Recuperación se eleva mucho más. Esto sin mencionar la pérdida de datos que tendrá lugar en el intermedio.
Otros beneficios importantes de tener despliegues multi-AZ incluyen:
- Sin retrasos de I/O durante respaldos, ya que los respaldos se toman de la instancia en espera.
- Sin interrupciones al I/O al aplicar parches o realizar actualizaciones para propósitos de mantenimiento.
- Aumento en la capacidad de respuesta cuando se usa balanceador de carga. Si una AZ está limitada, las instancias en otras zonas pueden procesar el tráfico.
Por supuesto, no todos los casos de uso de aplicaciones requieren un despliegue multi-AZ. Pruebas temporales, despliegues de desarrollo, o cualquier caso de uso que no sea crítico puede alojarse en una AZ única y evitar los costos adicionales que vienen con ejecutar un multi-AZ. Incluso hay casos de uso de alta intensidad y latencia extremadamente baja que se adaptan mejor al modelo de AZ única.
AWS Placement Groups
En pocas palabras, un Placement Group es una opción de configuración que AWS ofrece que te permite colocar un grupo de instancias interdependientes de cierta manera a través del hardware subyacente en el que residen esas instancias. Las instancias podrían colocarse cerca unas de otras, distribuidas a través de diferentes racks, o distribuidas a través de diferentes Zonas de Disponibilidad. Echemos un vistazo más de cerca a cada uno de los tipos de Placement Group que puedes elegir y tipos de cargas de trabajo que mejor se adaptarían a cada opción de distribución:
1. Cluster Placement Groups
La configuración de cluster placement group te permite colocar tu grupo de instancias interrelacionadas cerca unas de otras para lograr los mejores resultados posibles de rendimiento y baja latencia. Esta opción solo te permite empaquetar las instancias juntas dentro de la misma Zona de Disponibilidad, ya sea en la misma VPC o entre VPC emparejadas.
La ventaja con los cluster placement groups es que la comunicación entre esas instancias no está limitada al tráfico de flujo único de 5 Gbps sino a tráfico de flujo único (punto a punto) de 10 Gbps y un total de 25 Gbps para tráfico agregado. Las aplicaciones HPC (High Performance Computing) vinculadas a la red son los mejores casos de uso para este modelo de despliegue. Ingeniería computacional, transmisión de eventos en vivo, secuenciación genómica, modelos de astronomía y modelos de cómputo de clima terrestre son ejemplos de casos de uso para este tipo de agrupación en la nube.
2. Partition Placement Groups
Con partition placement groups, puedes agrupar tus instancias en particiones lógicas separadas que forman el placement group. La idea de esto es tener cada una de las particiones lógicas construida sobre racks de hardware separados para evitar fallos comunes de hardware. Si un rack falla, solo afectará las instancias que residen en esta partición lógica. Cada partición lógica está compuesta de múltiples instancias. La opción de partition placement group te permite colocar esas particiones dentro de una AZ única o en una configuración multi-AZ dentro de la misma región.
Entonces, ¿qué tipo de cargas se adaptarían mejor a este modelo? Los almacenes de big data que necesitan ser distribuidos y replicados son buenos ejemplos. Sistemas de archivos grandes como HDFS o Cassandra también son excelentes opciones. Los partition placement groups te permiten ver qué instancias se colocan en qué particiones para que puedas hacer que Hadoop o Cassandra sean conscientes de la topología y configurar la replicación de datos apropiadamente. Cualquier caso de uso que necesite análisis de big data, reportes de datos o indexación a gran escala también sería una buena opción para partition placement groups.
3. Spread Placement Groups
Con spread placement groups, cada instancia individual se ejecuta en racks de hardware físico separados. Entonces, si despliegas cinco instancias y las pones en este tipo de placement group, cada una de esas cinco instancias residirá en un rack diferente con su propio acceso de red y energía, ya sea dentro de una AZ única o en arquitectura multi-AZ.
La configuración de spread placement group puede ser similar a los partition placement groups, pero la diferencia principal es que los partition placement groups están hechos de varias instancias en cada partición, mientras que los spread groups son solo instancias individuales distribuidas a través de diferentes racks o AZ.
Este modelo se recomienda para un pequeño número de instancias críticas para tu negocio. Podrías tal vez tener una pequeña cantidad de instancias de base de datos SQL ejecutándose aquí o tu nivel de aplicación web. Esta configuración es un caso de uso ideal para redundancia ya que hay menos requisito para el poder computacional robusto ofrecido por partition y cluster placement groups.
Cloud Volumes ONTAP HA para AWS
La configuración Cloud Volumes ONTAP HA proporciona alta disponibilidad de AWS. Ejecutándose en nodos duales de instancias de cómputo Amazon EC2 y almacenando todos los datos en el almacenamiento Amazon EBS subyacente, las operaciones pueden prevenir que ocurra cualquier pérdida de datos en un fallo y recuperarse en menos de 60 segundos.
En este par de Cloud Volumes ONTAP, todos los datos se replican entre los dos nodos, ya sea en una configuración activo-activo, donde ambos nodos sirven clientes, o en una configuración activo-pasivo, en la cual un nodo está en espera. En ambos casos los datos se replican sincrónicamente cada vez que hay nuevos datos escritos. Esta configuración también puede desplegarse ya sea en un escenario de AZ única o en un escenario multi-AZ:
- AZ única: ambos nodos de Cloud Volumes ONTAP residen en la misma Zona de Disponibilidad. NetApp Cloud Manager despliega automáticamente ambos nodos con una configuración de spread placement group para evitar fallos comunes de cómputo.
- Multi-AZ: cada nodo de Cloud Volumes ONTAP reside en una Zona de Disponibilidad diferente, eliminando nuevamente la AZ como punto único de fallo, lo cual no es una característica que ofrece la replicación nativa de almacenamiento Amazon EBS. Con este tipo de configuración de alta disponibilidad necesitas configurar un AWS Transit Gateway con direcciones IP flotantes para que el failover funcione apropiadamente y proporcione acceso permanente NAS o cualquier acceso a datos.
Cloud Volumes ONTAP HA necesita tres instancias Amazon EC2 para funcionar: dos nodos principales haciendo todo el trabajo de almacenamiento y una instancia mediadora pequeña t2.micro a cargo de regular y administrar las tareas automáticas relacionadas con failover y failback. RPO (Recovery Point Objective) es cero, tus datos siempre son consistentes ya que se replican sincrónicamente, y tu RTO (Recovery Time Objective) es de 60 segundos o menos para que los datos estén disponibles nuevamente en caso de un failover al otro nodo.
AWS tiene otras características nativas de redundancia de capa de almacenamiento como Amazon EBS. Como se mencionó anteriormente, Amazon EBS solo replica dentro de servidores en una sola Zona de Disponibilidad y si fueras a proporcionar redundancia a nivel de almacenamiento usando solo Amazon EBS, necesitarías tomar snapshots de Amazon S3 y transferirlos a una Zona de Disponibilidad diferente, lo cual también tiene un costo adicional. Otras características nativas de alta disponibilidad de AWS como Amazon EFS exportan los datos almacenados solo a través de NFS, y actualmente no soporta instancias Windows.
Conclusión
Toda la información proporcionada en este artículo sobre mejores prácticas de alta disponibilidad de AWS nos lleva a tres conclusiones principales:
- Donde sea que haya una configuración multi-AZ presente, se anota un punto de confiabilidad adicional ya que la Zona de Disponibilidad completa en sí misma se descarta como punto único de fallo.
- Diferentes cargas de trabajo tienen diferentes conjuntos de requisitos que pueden adaptarse mejor ya sea a despliegues de AZ única o despliegues multi-AZ.
- Cuando sea que se necesite almacenamiento centralizado, Cloud Volumes ONTAP HA es una solución que aporta redundancia y recuperación rápida en la capa de almacenamiento, ya sea que estés desplegando en una modalidad de AZ única o en una multi-AZ. Esto a un precio menor o comparable comparado con ejecutar en almacenamiento Amazon EBS crudo.
Tu continuidad del negocio es importante. Cloud Volumes ONTAP te da la capacidad de asegurarla.