Zonas de disponibilidade da AWS, regiões e grupos de posicionamento explicados
Compartilhe esta página

Aviv Degani
Organizações empresariais utilizam aplicações que exigem diferentes níveis de disponibilidade e diferentes objetivos de SLA. O quão crítica ou exigente uma aplicação é considerado é proporcional aos seus requisitos de throughput, capacidade de resposta e tempo de recuperação em caso de falha. As mesmas considerações se aplicam ao formar as melhores práticas de alta disponibilidade da AWS.
Dependendo dos requisitos específicos da implantação, distribuir computação e armazenamento entre Zonas de Disponibilidade da AWS em combinação com Placement Groups é uma forma de abordar esse desafio em alta disponibilidade da AWS. Uma combinação otimizada dessas opções, juntamente com uma implantação Cloud Volumes ONTAP HA, pode atender aos requisitos apresentados por cada camada.
Neste artigo, vamos revisar essas melhores práticas de alta disponibilidade da AWS e casos de uso para Zonas de Disponibilidade únicas e múltiplas, e Placement Groups. Também veremos os benefícios adicionais que Cloud Volumes ONTAP HA pode trazer como solução na camada de storage.
Neste artigo, você aprenderá:
- O que são AWS Regions e Availability Zones?
- Parâmetros a considerar ao escolher uma AWS Region
- O que é uma implantação Multi-AZ?
- AWS Placement Groups
- Cloud Volumes ONTAP HA para AWS
O que são AWS Regions e Availability Zones?
As availability zones são data centers altamente disponíveis dentro de cada AWS region. Uma region representa uma área geográfica separada. Cada availability zone possui energia, refrigeração e rede independentes. Quando uma availability zone inteira fica indisponível, a AWS consegue transferir as cargas de trabalho para uma das outras zonas na mesma region, um recurso conhecido como redundância “Multi-AZ”.
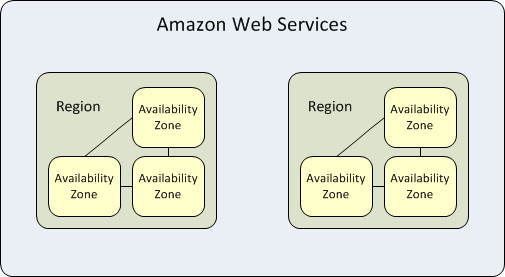
Cada AWS region é isolada e opera independentemente de outras regions, mas as availability zones dentro de cada region são conectadas por links de baixa latência para fornecer replicação e tolerância de falhas. Se você hospedar todos os seus dados e instâncias em uma única availability zone, que for afetada por uma falha, eles não estarão disponíveis.
O objetivo desse isolamento é atender cargas de trabalho com altos requisitos de soberania de dados e conformidade que não permitem que dados de usuário saiam de uma região geográfica específica. Esses tipos de cargas de trabalho se beneficiam da estrutura das AWS availability zones com baixa latência e separação completa de outras regions.
Veja uma lista completa de regions disponíveis dentro da infraestrutura global da AWS.
AWS Regions vs. Availability Zones
Existem duas principais diferenças operacionais entre executar suas cargas de trabalho em diferentes regions vs. diferentes availability zones dentro da mesma region.
Distribuição geográfica
A distribuição geográfica das AWS regions e availability zones também desempenha um papel significativo no desempenho e confiabilidade dos seus aplicativos.
Se você implantar seu aplicativo em várias availability zones em uma única region, pode alcançar um certo nível de alta disponibilidade e tolerância a falhas, mas menor do que o fornecido ao implantar em diferentes regions. Se uma availability zone falhar, seu aplicativo pode continuar rodando em outra availability zone sem qualquer interrupção. No entanto, se toda a region falhar, seu aplicativo falhará.
Por outro lado, implantar seu aplicativo em múltiplas regions significa que, mesmo que uma region inteira falhe (um cenário muito improvável), seu aplicativo pode continuar funcionando. Implantar em diferentes regions oferece benefícios adicionais, como latência reduzida para seus usuários globais e recuperação de desastres mais rápida.
Custo de computação e transferência de dados
Quando se trata de custo, a localização dos seus recursos AWS pode ter um impacto significativo. Cada AWS region tem preços diferentes para os serviços devido a fatores como demanda local, custos de infraestrutura e leis tributárias locais. Por exemplo, executar uma instância EC2 na região Asia Pacific (Mumbai) provavelmente custará mais do que executar a mesma instância na região US East (N. Virginia). No entanto, o custo de executar cargas de trabalho em diferentes AZs na mesma region geralmente é o mesmo.
Além disso, os custos de transferência de dados podem variar dependendo se os dados são transferidos dentro da mesma region, entre diferentes regions ou entre regions e a internet pública. Transferir dados dentro da mesma region ou entre availability zones na mesma region geralmente é mais barato do que transferir dados entre regions ou para a internet pública.
Parâmetros a considerar ao escolher uma AWS Region
Alguns parâmetros são essenciais para considerar antes de escolher uma AWS region e AZ para hospedar e implantar seu aplicativo para obter os melhores resultados.
A lista a seguir apresenta os parâmetros mais importantes a serem considerados:
Parâmetro #1: latência e proximidade— opte pela region mais próxima para baixa latência.
Uma conexão rápida com o servidor garante melhor desempenho em termos de carregamento e transferência rápidos, resultando em uma melhor experiência do usuário. Você pode conseguir isso escolhendo uma AWS region que seja a mais próxima da maioria da base de clientes. Quanto menor a distância entre a nuvem e o usuário final, menor a latência. Por exemplo, se a maioria dos seus clientes acessa seu aplicativo dentro da região da América do Norte, escolher uma availability zone dentro das regions dos EUA ou Canadá gerará os melhores resultados.
Os preços dos serviços AWS variam de acordo com a region, com base em elementos como custo da infraestrutura física e impostos. A diferença entre várias regions pode chegar a centenas de dólares, então escolher a certa é fundamental para reduzir custos desnecessários. Você pode usar a calculadora oficial de preços para ver qual region melhor atende às suas necessidades. Confira também a NetApp AWS Calculator, que permite calcular o TCO incluindo o custo dos serviços de storage.
Parâmetro #2: custo— escolha uma region que ofereça a melhor relação preço-desempenho.
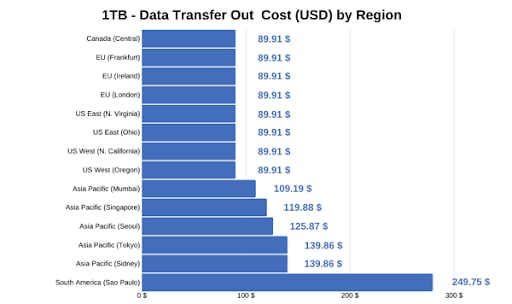
Abaixo está uma tabela de referência que mostra os vários preços para cada region para uma transferência de dados de 1TB.
Parâmetro #3: conformidade regulatória e segurança—proteger os ativos da empresa
Cada país ou união possui um conjunto diferente de normas e regras de conformidade para proteger dados de usuário. Algumas regions podem proibir a transferência entre sua region e outras regions. A violação dessas normas de conformidade pode levar a processos judiciais e resultar em danos financeiros e de reputação críticos para sua organização. Além disso, se você oferece serviços globais, deve considerar o uso de múltiplas AWS regions e availability zones para oferecer o serviço mais rápido e confiável para seus clientes.
Parâmetro #4: Service Level Agreements (SLA)— parâmetros corretos para obter melhor serviço.
Os serviços AWS oferecem diferentes SLAs com base em sua disponibilidade e parâmetros exclusivos. A AWS cumprirá o SLA melhor quando você implantar o aplicativo de acordo com o design AWS. Leve em consideração todos os outros parâmetros junto com seus requisitos ao selecionar uma region e uma AZ para garantir que ofereçam a melhor solução para hospedar e implantar seu aplicativo.
O que é uma implantação Multi-AZ?
Quando se trata de workloads de missão crítica, como bancos de dados corporativos— sejam hospedados em instâncias Amazon EC2 ou em serviços nativos de banco de dados Amazon (como Amazon RDS)—um modelo de distribuição multi-AZ oferece alta disponibilidade caso ocorra uma falha grave em toda uma Availability Zone.
Aplicações de produção críticas que não podem tolerar nem mesmo um tempo de inatividade moderado se beneficiam desse modelo e precisam considerar esse tipo de falha geral como uma possibilidade real. O mesmo vale para as camadas superiores que esse aplicativo pode ser composto. Se os serviços web de um app estiverem todos hospedados em uma única AZ, ter os bancos de dados subjacentes em uma configuração HA multi-AZ não ajudará muito se a camada web estiver hospedada em apenas uma AZ.
Dessa perspectiva de alta disponibilidade, em uma implantação de AZ única, se a AZ cair tudo cai e o tempo de recuperação vai ser muito maior. Sem mencionar a perda de dados que ocorrerá nesse intervalo.
Outros benefícios importantes de ter implantações multi-AZ incluem:
- Sem atrasos de I/O durante backups, pois os backups são feitos a partir da instância standby.
- Sem interrupções de I/O ao aplicar patches ou realizar upgrades para manutenção.
- Aumento da capacidade de resposta quando o balanceamento de carga é utilizado. Se uma AZ estiver sobrecarregada, as instâncias em outras zones podem absorver o tráfego.
Claro, nem todos os casos de uso de aplicação exigem uma implantação multi-AZ. Testes temporários, implantações de desenvolvimento ou qualquer caso de uso não crítico podem ser hospedados em uma única AZ e evitar os custos adicionais de rodar um multi-AZ. Existem até casos de uso de alta intensidade e latência extremamente baixa que se encaixam melhor no modelo de AZ única.
AWS Placement Groups
De forma simples, um Placement Group é uma opção de configuração que a AWS oferece e que permite posicionar um grupo de instâncias interdependentes de determinada forma no hardware subjacente onde essas instâncias residem. As instâncias podem ser posicionadas próximas, espalhadas por diferentes racks ou espalhadas por diferentes Availability Zones. Vamos analisar mais de perto cada um dos tipos de Placement Group que você pode escolher e os tipos de workloads que melhor se encaixam em cada opção de distribuição:
1. Cluster Placement Groups
A configuração de cluster placement group permite posicionar seu grupo de instâncias inter-relacionadas próximas para obter o melhor throughput e resultados de baixa latência possíveis. Essa opção só permite agrupar as instâncias juntas dentro da mesma Availability Zone, seja na mesma VPC ou entre VPCs emparelhadas.
A vantagem dos cluster placement groups é que a comunicação entre essas instâncias não se limita ao tráfego single-flow de 5 Gbps, mas a 10 Gbps single-flow (ponto a ponto) e um total de 25 Gbps para tráfego agregado. Aplicações HPC (High Performance Computing) dependentes de rede são os melhores casos de uso para esse modelo de implantação. Engenharia computacional, streaming de eventos ao vivo, sequenciamento genômico, modelos astronômicos e modelos computacionais de clima terrestre são exemplos de casos de uso para esse tipo de agrupamento na nuvem.
2. Partition Placement Groups
Com partition placement groups, você pode agrupar suas instâncias em partições lógicas separadas que formam o placement group. A ideia é que cada uma das partições lógicas seja construída sobre racks de hardware separados para evitar falhas comuns de hardware. Se um rack falhar, isso afetará apenas as instâncias residentes nessa partição lógica. Cada partição lógica é composta por múltiplas instâncias. A opção partition placement group permite posicionar essas partições dentro de uma única AZ ou em uma configuração multi-AZ dentro da mesma region.
Então, que tipo de cargas se encaixam melhor nesse modelo? Grandes data stores que precisam ser distribuídos e replicados são bons exemplos. Grandes sistemas de arquivos como HDFS ou Cassandra também são ótimos exemplos. Partition placement groups permitem ver quais instâncias estão em quais partições, assim você pode tornar Hadoop ou Cassandra cientes da topologia e configurar a replicação de dados corretamente. Qualquer caso de uso que exija análise de big data, geração de relatórios de dados ou indexação em larga escala também seria uma boa opção para partition placement groups.
3. Spread Placement Groups
Com spread placement groups, cada instância individual roda em racks físicos separados. Assim, se você implantar cinco instâncias e colocá-las nesse tipo de placement group, cada uma dessas cinco instâncias ficará em um rack diferente com seu próprio acesso à rede e energia, seja dentro de uma única AZ ou em arquitetura multi-AZ.
A configuração spread placement group pode ser semelhante aos partition placement groups, mas a principal diferença é que partition placement groups são compostos por várias instâncias em cada partição, enquanto spread groups são apenas instâncias individuais espalhadas por diferentes racks ou AZs.
Esse modelo é recomendado para um pequeno número de instâncias críticas para o seu negócio. Você pode, por exemplo, ter uma pequena quantidade de instâncias de banco de dados SQL rodando aqui ou sua camada de aplicativos web. Essa configuração é um caso de uso ideal para redundância, já que há menos necessidade do poder computacional robusto oferecido por partition e cluster placement groups.
Cloud Volumes ONTAP HA para AWS
A configuração Cloud Volumes ONTAP HA oferece alta disponibilidade AWS. Rodando em dois nós de instâncias Amazon EC2 e armazenando todos os dados no Amazon EBS storage, as operações podem evitar qualquer perda de dados em caso de falha e se recuperar em menos de 60 segundos.
Nesse par Cloud Volumes ONTAP, todos os dados são espelhados entre os dois nós, seja em uma configuração ativo-ativo, onde ambos os nós atendem clientes, ou em uma configuração ativo-passivo, na qual um nó é standby. Em ambos os casos, os dados são espelhados de forma síncrona cada vez que há novos dados gravados. Essa configuração também pode ser implantada em um cenário de AZ única ou em um cenário multi-AZ:
- Single-AZ: ambos os nós Cloud Volumes ONTAP residem na mesma Availability Zone. NetApp Cloud Manager implanta automaticamente ambos os nós com uma configuração spread placement group para evitar falhas comuns de computação.
- Multi-AZ: cada nó Cloud Volumes ONTAP reside em uma Availability Zone diferente, eliminando novamente a AZ como ponto único de falha, o que não é um recurso oferecido pela replicação nativa do Amazon EBS storage. Com esse tipo de configuração de alta disponibilidade, é necessário configurar um AWS Transit Gateway com endereços IP flutuantes para que o failover funcione corretamente e forneça acesso permanente NAS ou qualquer acesso a dados.
Cloud Volumes ONTAP HA precisa de três instâncias Amazon EC2 para funcionar: dois nós principais fazendo todo o trabalho de storage e uma pequena instância mediadora t2.micro responsável por regular e administrar as tarefas automáticas de failover e failback. O RPO (Recovery Point Objective) é zero, seus dados estão sempre consistentes pois são espelhados de forma síncrona, e o RTO (Recovery Time Objective) é de 60 segundos ou menos para os dados estarem disponíveis novamente em caso de failover para o outro nó.
A AWS possui outros recursos nativos de redundância na camada de storage, como Amazon EBS. Como mencionado anteriormente, o Amazon EBS só replica entre servidores em uma única Availability Zone e, se você quiser fornecer redundância na camada de storage usando apenas Amazon EBS, seria necessário tirar snapshots Amazon S3 e transferi-los para uma Availability Zone diferente, o que também tem custo adicional. Outros recursos nativos de alta disponibilidade da AWS, como Amazon EFS exportam os dados armazenados apenas via NFS, e atualmente não suportam instâncias Windows.
Conclusão
Todas as informações fornecidas neste artigo sobre as melhores práticas de alta disponibilidade AWS nos levam a três principais conclusões:
- Sempre que houver uma configuração multi-AZ, um ponto adicional de confiabilidade é conquistado, pois toda a Availability Zone é descartada como ponto único de falha.
- Diferentes workloads têm diferentes conjuntos de requisitos que podem se encaixar melhor em implantações single-AZ ou multi-AZ.
- Sempre que o storage centralizado for necessário, Cloud Volumes ONTAP HA é uma solução que traz redundância e recuperação rápida na camada de storage, seja em modalidade single-AZ ou multi-AZ. Isso a um preço menor ou comparável ao de rodar em storage Amazon EBS puro.
Sua continuidade dos negócios é importante. Cloud Volumes ONTAP oferece a capacidade de garantir isso.