Zones de disponibilité, régions et groupes de placement AWS expliqués
Partager cette page

Aviv Degani
Les entreprises utilisent des applications qui nécessitent différents niveaux de disponibilité et des objectifs de SLA variés. Le caractère critique ou exigeant d'une application est proportionnel à ses besoins en débit, en réactivité et en temps de récupération en cas de panne. Les mêmes considérations s'appliquent lors de l'élaboration des meilleures pratiques de haute disponibilité AWS.
Selon les exigences spécifiques du déploiement, répartir le calcul et le stockage entre les zones de disponibilité AWS, en combinaison avec les groupes de placement, est une façon de relever ce défi en matière de haute disponibilité AWS. Une combinaison optimisée de ces options, associée à un déploiement Cloud Volumes ONTAP HA, peut répondre aux exigences de chaque couche.
Dans cet article, nous allons passer en revue ces meilleures pratiques de haute disponibilité AWS et les cas d'usage pour les déploiements en zone unique et multi-zones, ainsi que pour les groupes de placement. Nous examinerons également les avantages supplémentaires que Cloud Volumes ONTAP HA peut apporter en tant que solution au niveau du stockage.
Dans cet article, vous apprendrez :
- Qu'est-ce que les régions et zones de disponibilité AWS ?
- Paramètres à prendre en compte lors du choix d'une région AWS
- Qu'est-ce qu'un déploiement Multi-AZ ?
- Groupes de placement AWS
- Cloud Volumes ONTAP HA pour AWS
Qu'est-ce que les régions et zones de disponibilité AWS ?
Les zones de disponibilité sont des centres de données hautement disponibles au sein de chaque région AWS. Une région représente une zone géographique distincte. Chaque zone de disponibilité dispose d'une alimentation, d'un refroidissement et d'un réseau indépendants. Lorsqu'une zone de disponibilité entière tombe en panne, AWS peut basculer les charges de travail vers une autre zone de la même région, une capacité appelée redondance « Multi-AZ ».
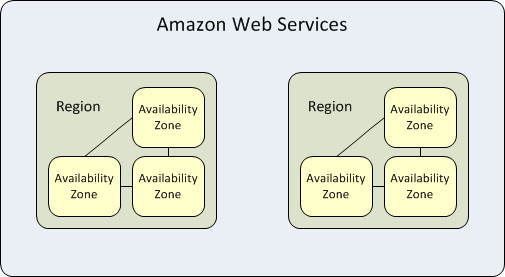
Chaque région AWS est isolée et fonctionne indépendamment des autres régions, mais les zones de disponibilité au sein de chaque région sont reliées par des liaisons à faible latence pour assurer la réplication et la tolérance aux pannes. Si vous hébergez toutes vos données et instances dans une seule zone de disponibilité, et qu'elle est affectée par une panne, elles ne seront pas disponibles.
L'objectif de cette isolation est de servir des charges de travail avec des exigences élevées en matière de souveraineté des données et de conformité, qui n'autorisent pas le passage des données utilisateur en dehors d'une région géographique spécifique. Ces types de charges de travail bénéficient de la structure des zones de disponibilité AWS, avec une faible latence et une séparation complète des autres régions.
Voir une liste complète des régions disponibles au sein de l'infrastructure mondiale AWS.
Régions AWS vs. zones de disponibilité
Il existe deux différences opérationnelles clés entre l'exécution de vos charges de travail dans différentes régions et dans différentes zones de disponibilité au sein d'une même région.
Répartition géographique
La répartition géographique des régions et des zones de disponibilité AWS joue également un rôle important dans la performance et la fiabilité de vos applications.
Si vous déployez votre application sur plusieurs zones de disponibilité dans une seule région, vous pouvez atteindre un certain niveau de haute disponibilité et de tolérance aux pannes, mais inférieur à celui offert par un déploiement dans différentes régions. Si une zone de disponibilité échoue, votre application peut continuer à fonctionner dans une autre zone sans interruption. Cependant, si toute la région échoue, votre application échouera.
En revanche, déployer votre application dans plusieurs régions signifie que même si une région entière échoue (un scénario très improbable), votre application peut continuer à fonctionner. Le déploiement entre régions offre des avantages supplémentaires tels qu'une latence réduite pour vos utilisateurs mondiaux et une reprise après sinistre plus rapide.
Coût du calcul et du transfert de données
En matière de coût, l'emplacement de vos ressources AWS peut avoir un impact significatif. Chaque région AWS applique des tarifs différents pour les services en fonction de facteurs tels que la demande locale, les coûts d'infrastructure et la législation fiscale locale. Par exemple, exécuter une instance EC2 dans la région APAC (Mumbai) coûtera probablement plus cher que d'exécuter la même instance dans la région US East (N. Virginia). Cependant, le coût d'exécution des charges de travail sur différentes zones de disponibilité dans une même région est généralement identique.
De plus, les coûts de transfert de données peuvent varier selon que les données sont transférées au sein d'une même région, entre différentes régions ou entre régions et Internet public. Le transfert de données au sein d'une même région ou entre zones de disponibilité d'une même région est généralement moins cher que le transfert de données entre régions ou vers Internet public.
Paramètres à prendre en compte lors du choix d'une région AWS
Certains paramètres sont essentiels à considérer avant de choisir une région et une zone de disponibilité AWS pour héberger et déployer votre application afin d'obtenir les meilleurs résultats.
La liste suivante présente les paramètres les plus importants à prendre en compte :
Paramètre n°1 : Latence et proximité— optez pour la région la plus proche pour une faible latence.
Une connexion rapide au serveur garantit de meilleures performances en termes de chargement et de transfert, ce qui se traduit par une meilleure expérience utilisateur. Vous pouvez y parvenir en choisissant une région AWS la plus proche de la majorité de votre base client. Plus la distance entre le cloud et l'utilisateur final est courte, plus la latence est faible. Par exemple, si la plupart de vos clients accèdent à votre application depuis la région Amérique du Nord, choisir une zone de disponibilité dans les régions des États-Unis ou du Canada offrira les meilleurs résultats.
Les prix des services AWS varient selon la région, en fonction d'éléments comme le coût de l'infrastructure physique et les taxes. La différence entre les régions peut atteindre plusieurs centaines de dollars, il est donc essentiel de bien choisir pour réduire les coûts inutiles. Vous pouvez utiliser le calculateur de prix officiel pour voir quelle région correspond le mieux à vos besoins. Consultez également le NetApp AWS Calculator, qui vous permet de calculer le TCO, y compris le coût des services de stockage.
Paramètre n°2 : Coût— choisissez une région offrant le meilleur rapport prix/performance.
Vous trouverez ci-dessous un tableau de référence présentant les différents prix pour chaque région pour un transfert de données de 1 To.
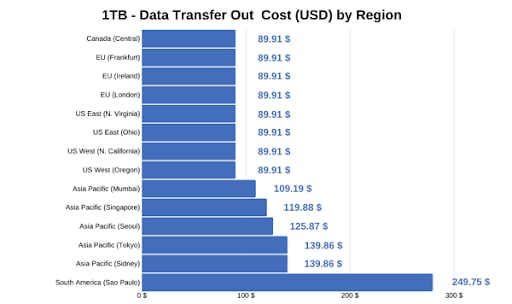
Paramètre n°3 : Conformité réglementaire et sécurité—protection des actifs de l'entreprise
Chaque pays ou union dispose de ses propres normes et règles de conformité pour protéger les données des utilisateurs. Certaines régions peuvent interdire le transfert entre leur région et d'autres régions. Une violation de ces réglementations de conformité peut entraîner des poursuites judiciaires et causer des dommages financiers et de réputation critiques à votre organisation. De plus, si vous proposez des services dans le monde entier, vous devriez envisager d'utiliser plusieurs régions et zones de disponibilité AWS pour offrir à vos clients le service le plus rapide et le plus fiable.
Paramètre n°4 : Accords de niveau de service (SLA)— les bons paramètres pour obtenir un meilleur service.
Les services AWS offrent différents SLA en fonction de leur disponibilité et de leurs paramètres spécifiques. AWS respectera au mieux le SLA lorsque vous déployez l'application selon la conception AWS. Prenez en compte tous les autres paramètres ainsi que vos exigences lors du choix d'une région et d'une zone de disponibilité afin de garantir qu'elles offrent la meilleure solution pour héberger et déployer votre application.
Qu'est-ce qu'un déploiement Multi-AZ ?
Pour les charges de travail critiques, telles que les bases de données d'entreprise— qu'elles soient hébergées sur des instances Amazon EC2 ou sur des services de base de données natifs Amazon (comme Amazon RDS)—un modèle de distribution multi-AZ vous offre une haute disponibilité en cas de panne majeure dans une zone de disponibilité entière.
Les applications de production critiques qui ne peuvent pas se permettre la moindre interruption bénéficient de ce modèle et doivent considérer ce type de panne générale comme une réelle possibilité. Il en va de même pour les couches supérieures dont cette application peut être composée. Si les services web d'une application sont tous hébergés dans une seule AZ, avoir les bases de données sous-jacentes en configuration HA multi-AZ n'apportera pas grand-chose si le tier web est hébergé dans une seule AZ.
Dans cette perspective de haute disponibilité, dans un déploiement mono-AZ, si la zone tombe, tout tombe et l'objectif de temps de récupération augmente considérablement. Sans parler de la perte de données qui aura lieu entre-temps.
Parmi les autres avantages importants des déploiements multi-AZ, citons :
- Aucun délai d'E/S lors des sauvegardes, car les sauvegardes sont effectuées à partir de l'instance de secours.
- Aucune interruption d'E/S lors de l'application de correctifs ou de la réalisation de mises à niveau pour la maintenance.
- Augmentation de la réactivité lorsque l'équilibrage de charge est utilisé. Si une AZ est contrainte, les instances dans les autres zones peuvent absorber le trafic.
Bien entendu, tous les cas d'usage applicatifs ne nécessitent pas un déploiement multi-AZ. Les tests temporaires, les déploiements de développement ou tout cas d'usage non critique peuvent être hébergés dans une seule AZ et éviter les coûts supplémentaires liés à l'exécution d'un multi-AZ. Il existe même des cas d'usage à forte intensité et à latence extrêmement faible qui conviennent mieux au modèle mono-AZ.
Groupes de placement AWS
En résumé, un groupe de placement est une option de configuration proposée par AWS qui vous permet de placer un groupe d'instances interdépendantes d'une certaine manière sur le matériel sous-jacent où résident ces instances. Les instances peuvent être placées à proximité les unes des autres, réparties sur différents racks ou réparties sur différentes zones de disponibilité. Examinons de plus près chaque type de groupe de placement que vous pouvez choisir et les types de charges de travail qui conviendraient le mieux à chaque option de distribution :
1. Groupes de placement en cluster
La configuration de groupe de placement en cluster vous permet de placer votre groupe d'instances interdépendantes à proximité afin d'obtenir le meilleur débit et la latence la plus faible possible. Cette option vous permet uniquement de regrouper les instances ensemble dans la même zone de disponibilité, soit dans le même VPC, soit entre des VPC appariés.
L'avantage des groupes de placement en cluster est que la communication entre ces instances n'est pas limitée à un trafic à flux unique de 5 Gbps mais à 10 Gbps en flux unique (point à point) et à un total de 25 Gbps pour le trafic agrégé. Les applications HPC (High Performance Computing) nécessitant un accès réseau sont les meilleurs cas d'usage pour ce modèle de déploiement. Le calcul scientifique, la diffusion d'événements en direct, le séquençage génomique, les modèles astronomiques et les modèles de calcul climatique terrestre sont des exemples de cas d'usage pour ce type de regroupement dans le cloud.
2. Groupes de placement de partitions
Avec les groupes de placement de partitions, vous pouvez regrouper vos instances dans des partitions logiques distinctes qui forment le groupe de placement. L'idée est que chaque partition logique soit construite sur des racks matériels séparés afin d'éviter les pannes matérielles communes. Si un rack tombe en panne, cela n'affectera que les instances résidant sur cette partition logique. Chaque partition logique est composée de plusieurs instances. L'option de groupe de placement de partitions vous permet de placer ces partitions dans une seule AZ ou dans une configuration multi-AZ au sein de la même région.
Alors, quels types de charges conviendraient le mieux à ce modèle ? Les grands magasins de données nécessitant d'être distribués et répliqués en sont de bons exemples. Les grands systèmes de fichiers comme HDFS ou Cassandra sont également de très bons candidats. Les groupes de placement de partitions vous permettent de voir quelles instances sont placées dans quelles partitions afin de rendre Hadoop ou Cassandra topologiquement conscients et de configurer correctement la réplication des données. Tout cas d'usage nécessitant une analyse de big data, des rapports de données ou un indexage à grande échelle conviendra également aux groupes de placement de partitions.
3. Groupes de placement répartis
Avec les groupes de placement répartis, chaque instance unique s'exécute sur des racks matériels physiques séparés. Ainsi, si vous déployez cinq instances et les placez dans ce type de groupe de placement, chacune de ces cinq instances résidera sur un rack différent avec son propre accès réseau et alimentation, soit dans une seule AZ, soit dans une architecture multi-AZ.
La configuration des groupes de placement répartis peut sembler similaire à celle des groupes de placement de partitions, mais la principale différence est que les groupes de placement de partitions sont composés de plusieurs instances par partition, tandis que les groupes répartis ne sont que des instances individuelles réparties sur différents racks ou AZ.
Ce modèle est recommandé pour un petit nombre d'instances critiques pour votre entreprise. Vous pourriez par exemple avoir un petit nombre d'instances SQL database ou votre tier applicatif exécutées ici. Cette configuration est un cas d'usage idéal pour la redondance puisqu'il y a moins de besoin de puissance de calcul importante offerte par les groupes de placement de partitions et de clusters.
Cloud Volumes ONTAP HA pour AWS
La configuration Cloud Volumes ONTAP HA fournit la haute disponibilité AWS. Fonctionnant sur deux nœuds d'instances de calcul Amazon EC2 et stockant toutes les données dans le stockage Amazon EBS, les opérations peuvent empêcher toute perte de données en cas de panne et récupérer en moins de 60 secondes.
Dans cette paire Cloud Volumes ONTAP, toutes les données sont répliquées entre les deux nœuds, soit en configuration active-active, où les deux nœuds servent les clients, soit en configuration active-passive, dans laquelle un nœud est en veille. Dans les deux cas, les données sont répliquées de façon synchrone à chaque nouvelle écriture. Cette configuration peut aussi être déployée soit dans un scénario mono-AZ, soit dans un scénario multi-AZ :
- Mono-AZ : Les deux nœuds Cloud Volumes ONTAP résident dans la même zone de disponibilité. NetApp Cloud Manager déploie automatiquement les deux nœuds avec une configuration de groupe de placement réparti afin d'éviter les pannes de calcul courantes.
- Multi-AZ : Chaque nœud Cloud Volumes ONTAP réside dans une zone de disponibilité différente, éliminant ainsi la zone de disponibilité comme point de défaillance unique, ce qui n'est pas une fonctionnalité offerte par la réplication native du stockage Amazon EBS. Avec ce type de configuration haute disponibilité, vous devez mettre en place une passerelle de transit AWS avec des adresses IP flottantes pour que le basculement fonctionne correctement et fournisse un accès NAS permanent ou tout accès aux données.
Cloud Volumes ONTAP HA nécessite trois instances Amazon EC2 pour fonctionner : deux nœuds principaux assurant tout le travail de stockage et une petite instance médiateur t2.micro chargée de réguler et d'administrer les tâches automatiques de basculement et de restauration. Le RPO (Recovery Point Objective) est nul, vos données sont toujours cohérentes puisqu'elles sont répliquées de façon synchrone, et votre RTO (Recovery Time Objective) est de 60 secondes ou moins pour que les données soient à nouveau disponibles en cas de basculement vers l'autre nœud.
AWS propose d'autres fonctionnalités natives de redondance au niveau du stockage, telles qu'Amazon EBS. Comme mentionné précédemment, Amazon EBS ne réplique qu'entre les serveurs d'une seule zone de disponibilité et si vous souhaitez assurer la redondance au niveau du stockage en utilisant uniquement Amazon EBS, vous devrez prendre des snapshots Amazon S3 et les transférer vers une autre zone de disponibilité, ce qui a également un coût supplémentaire. D'autres fonctionnalités natives de haute disponibilité AWS telles que Amazon EFS exportent les données stockées uniquement via NFS, et ne prennent actuellement pas en charge les instances Windows.
Conclusion
Toutes les informations fournies dans cet article sur les meilleures pratiques de haute disponibilité AWS nous amènent à trois principales conclusions :
- Dès qu'une configuration multi-AZ est présente, un point de fiabilité supplémentaire est acquis car la zone de disponibilité entière elle-même n'est plus un point de défaillance unique.
- Différentes charges de travail ont des exigences différentes qui peuvent mieux convenir à des déploiements mono-AZ ou multi-AZ.
- Dès qu'un stockage centralisé est nécessaire, Cloud Volumes ONTAP HA est une solution qui apporte redondance et récupération rapide au niveau du stockage, que vous déployiez en mode mono-AZ ou multi-AZ. Cela à un prix inférieur ou comparable à celui de l'exécution sur du stockage Amazon EBS brut.
La continuité de votre activité est importante. Cloud Volumes ONTAP vous donne la possibilité de l'assurer.