Was ist Datendeduplizierung?
Diese Seite teilen
Datendeduplizierung ist ein Prozess, der überflüssige Datenkopien beseitigt und die benötigte Storage-Kapazität deutlich verringert.
Eine Deduplizierung kann als Inline-Prozess beim Schreiben der Daten auf das Storage-System und/oder als Hintergrundprozess zur Beseitigung von Duplikaten nach dem Schreiben der Daten durchgeführt werden.
Bei NetApp ist Deduplizierung eine Technologie ohne jeglichen Datenverlust, die sowohl als Inline-Prozess als auch als Hintergrundprozess ausgeführt wird, um Einsparungen zu maximieren. Deduplizierung wird (in der Regel) möglichst als Inline-Prozess ausgeführt, sodass sie den Client-Betrieb nicht stört. Um die Einsparungen zu maximieren, läuft zusätzlich der vollständige/komplette Prozess im Hintergrund. Die Deduplizierung ist standardmäßig aktiviert, und das System führt sie automatisch auf allen Volumes und Aggregaten ohne manuellen Eingriff aus.
Der Performance-Overhead durch die Deduplizierungsoperationen ist minimal, da diese in einer eigenen Domain ausgeführt werden, die von der Domain für Lese-/und Schreiboperationen der Clients getrennt ist. Deduplizierung läuft unbemerkt, unabhängig von der ausgeführten Applikation und der Art des Datenzugriffs (NAS oder SAN).
Einsparungen durch Deduplizierung bleiben beim Verschieben der Daten erhalten – wenn sie auf einen Disaster-Recovery-Standort repliziert werden, in einem Vault gesichert oder zwischen On-Premises, Hybrid Cloud und/oder Public Cloud verschoben werden.
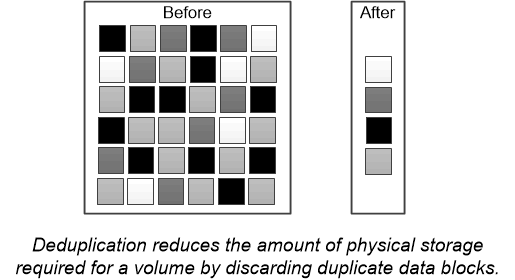
Wie funktioniert Deduplizierung?
Deduplizierung erfolgt auf 4-KB-Block-Ebene innerhalb eines gesamten FlexVol Volumes und über alle Volumes innerhalb eines Aggregats hinweg, wodurch doppelte Datenblöcke beseitigt und nur einzigartige Datenblöcke gespeichert werden.
Die Basistechnologie der Deduplizierung sind Checksummen – eindeutige digitale Signaturen für alle 4-KB-Datenblöcke.
Wenn Daten in das System geschrieben werden, scannt die Inline-Deduplizierungs-Engine die eingehenden Blöcke, erstellt eine Checksumme und speichert diese in einem Hash-Speicher (In-Memory-Datenstruktur).
Nachdem die Checksumme berechnet wurde, wird geprüft, ob diese sich im Hash-Speicher befindet. Bei einem Auffinden der Checksumme im Hash-Speicher wird der Datenblock mit derselben Checksumme (Spenderblock) im Cache-Speicher gesucht:
- Wird er gefunden, werden der aktuelle Datenblock (Empfängerblock) und der Spenderblock zur Verifikation Byte für Byte miteinander verglichen, um eine genaue Übereinstimmung sicherzustellen. Nach erfolgreicher Verifikation wird der Empfängerblock mit dem passenden Spenderblock geteilt, ohne dass der Empfängerblock tatsächlich auf die Festplatte geschrieben wird. Nur die Metadaten werden aktualisiert, um die Sharing-Informationen festzuhalten.
- Wenn der Spenderblock nicht im Cache-Speicher gefunden wird, wird der Spenderblock erst von Platte in den Cache geladen, um dann einen Byte-für-Byte-Vergleich durchzuführen und so eine genaue Übereinstimmung sicherzustellen. Nach erfolgter/erfolgreicher Überprüfung wird der Empfängerblock als Duplikat gekennzeichnet, ohne dass tatsächlich auf Platte geschrieben wird. Die Metadaten werden aktualisiert, um die Sharing-Informationen festzuhalten.
Die Deduplizierungs-Engine im Hintergrund funktioniert auf die gleiche Weise. Sie scannt alle Datenblöcke im Aggregat und beseitigt Duplikate, indem sie die Checksummen der Blöcke vergleicht und einen Byte-für-Byte-Vergleich durchführt, um falsch positive Ergebnisse (False Positives) zu unterbinden. Dieses Verfahren stellt auch sicher, dass während der Deduplizierung keine Daten verloren gehen.
Vorteile der NetApp Deduplizierung
Die NetApp Deduplizierung bietet einige wesentliche Vorteile:
- kann mit NetApp Systemen oder Primär-, Sekundär- und Archiv-Storage von Drittanbietern verwendet werden
- anwendungsunabhängig
- protokollunabhängig
- minimaler Aufwand
- funktioniert mit NetApp AFF, FAS
- Byte-für-Byte-Validierung
- kann auf neue Daten oder auf bereits in Volumes und LUNs gespeicherte Daten angewendet werden
- kann außerhalb der Spitzenlastzeiten ausgeführt werden
- integriert in andere NetApp Storage-Effizienztechnologien
- Einsparungen durch Deduplizierung gehen nicht verloren, wenn die NetApp SnapMirror Replizierungstechnologie oder das intelligente Caching von Flash Cache verwendet wird
- kostenlos
Anwendungsfälle der Deduplizierung
Deduplizierung ist unabhängig von der Art des Workloads sinnvoll. Der maximale Nutzen zeigt sich in virtuellen Umgebungen, in denen eine Vielzahl von virtuellen Maschinen für Test-/Entwicklungs-Abläufe und Applikationsentwicklung verwendet werden.
Desktop-Virtualisierung (VDI) ist ein weiterer sehr guter Kandidat für die Deduplizierung, da bei Desktops doppelte Daten in großem Umfang anfallen.
Einige relationale Datenbanken wie Oracle und SQL profitieren nicht so sehr von der Deduplizierung, da sie oft einen eindeutigen Schlüssel für jeden Datenbankeintrag haben. Dies verhindert, dass die Deduplizierungs-Engine sie als Duplikate identifiziert.
Deduplizierung konfigurieren
Die Deduplizierung ist für alle neuen Volumes und Aggregate auf All Flash FAS Systemen automatisch aktiviert. Auf anderen Systemen kann die Deduplizierung auf Volume- und/oder Aggregatebene aktiviert werden.
Nach der Aktivierung führt das System automatisch sowohl Inline- als auch Hintergrunddeduplizierung aus, um maximale Einsparungen zu erzielen.
.png?width=5760&format=avif&disable=upscale)