The intertwining of Industry 4.0 and AI transformation

Share this page

Muneer Ahmad Dedmari
Industry 4.0 refers to the current trend of automation and data exchange in manufacturing technologies, including developments in artificial intelligence, the Internet of Things (IoT), and cloud computing. These technologies improve the efficiency and productivity of industries, help them to meet the needs of the global population, and enable new data-driven business models. Because Industry 4.0 involves the integration of digital and physical systems, it enables the seamless communication and exchange of data between machines and people.
Industry 4.0 improves efficiency and productivity in manufacturing processes. With the use of data from sensors and data analytics, it allows organizations to monitor and optimize the production line in real time. It also has other applications in a wide range of industries, including automotive, aerospace, healthcare, consumer goods, and more. Industry 4.0 can potentially help companies cut costs by incorporating automation and enabling them to manufacture products that match shifting market demands. Continuous research and innovation are driving the adoption of Industry 4.0. According to a Fortune Business Insights report, the global Industry 4.0 market is projected to grow from $130.90 billion in 2022 to $377.30 billion by 2029.
In general, the goal of Industry 4.0 is to create a more responsive, efficient, and flexible ecosystem that can adapt to changing market trends and customer needs in real time. However, one might ask “How can Industry 4.0 be implemented?”
There is a need for middleware that digitizes and connects the ever-changing industry workflows. This middleware must be capable of integrating different machines, and it must provide a unified communication between them and people. The Eclipse BaSyx software platform is designed to enable the integration and optimization of relevant technologies, including artificial intelligence, IoT, and cloud computing into a single cohesive system. It is middleware that supports the implementation of digital twins for Industry 4.0 production environments and therefore connects essential assets with each other for end-to-end digitization.
Why BaSyx?
Eclipse BaSyx integrates with a wide range of open-source tools to build an Industry 4.0 ecosystem and offers ready-to-use applications, unlike other Industry 4.0 solutions.
It also facilitates data collection and gives it a structured form through the asset administration shell (AAS), which is the technical foundation for digital twins created with BaSyx. The AAS creates a digital replica of both physical and non-physical assets, like products, orders, processes, devices, certificates, etc. Therefore, AAS is the digital representation of Industry 4.0 assets, and each asset has a unique identifier associated with it. AAS provides a common schema for representing the characteristics and digital assets and their relationship with other assets and systems.
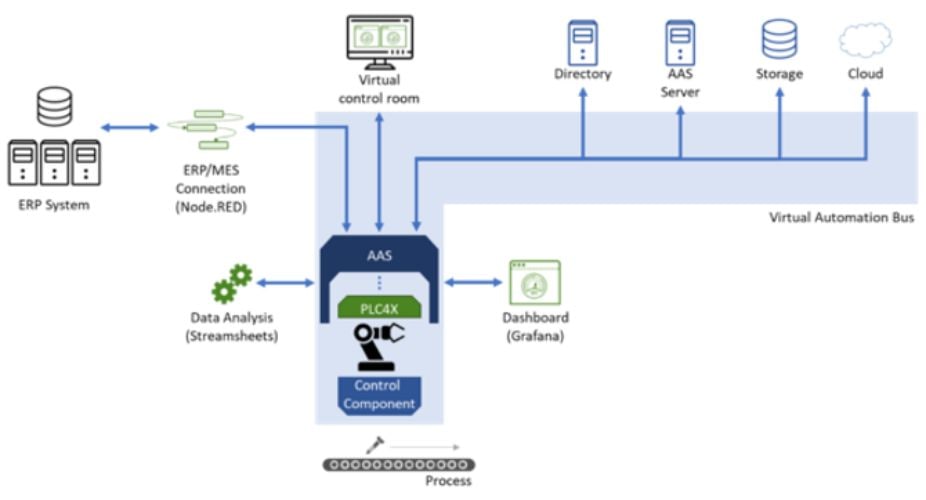
Challenges of implementing Industry 4.0 and a possible solution
The last few years have witnessed the growth of the Internet of Things from a mere concept to a reality. In 2019 the number of IoT devices was 7.74 billion; that number is expected to reach 25.44 billion by 2030. With the increasing adoption of IoT, data generation is growing exponentially. According to a report by DataPort, the amount of data generated by IoT devices in 2019 was 17.3 zettabytes (ZB), and it's expected to reach 73.1ZB by 2025.
Imagine that this much data is generated by IoT devices alone. Other processes and devices are constantly communicating with IoT devices and generating more data. For analytics and artificial intelligence, this raw data from the devices and processes is leveraged to derive valuable intelligence. Usually, crude data is not used as such; it needs to be processed so that the high-quality data is feed for analytics and AI. These workloads not only use existing data, they also create more data on the fly. The velocity of data is increasing dramatically, and so is the need for data management and storage.
One solution to this problem is to use object storage to store and manage the data of physical and nonphysical assets. Object storage is a type of data storage architecture designed for storing large volumes of data. Unlike other types of storage, object storage stores data as distinct units (Objects) clustered with metadata, and a unique ID is used for locating and accessing each unit of data. Rather than hierarchical storage (block or file storage), object storage creates flat (bucket) storage that makes it possible to retrieve any object in a "bucket", regardless of file type. Using object storage to store the data related to assets in the context of Industry 4.0 helps to make the data more accessible and also facilitates the management and optimization of the asset. Object storage offers a wide range of advantages like cost effectiveness, flexibility, user friendliness, scalability, and durability, which makes it best suited for Industry 4.0 solutions.
Industry 4.0: Better with NetApp and Fraunhofer
Together with Fraunhofer, NetApp provides a comprehensive platform for Industry 4.0 that offers the ability to efficiently withstand the amount of heterogenous data generated and used by the system. With Eclipse BaSyx together with object storage, we have developed a robust solution that standardizes Industry 4.0 by means of AAS. AAS creates assets and related data as S3 objects and stores them to NetApp® StorageGRID®.
This joint solution gives you a ready-made, easy-to-use architecture for rapidly commissioning Industry 4.0 in your organization.
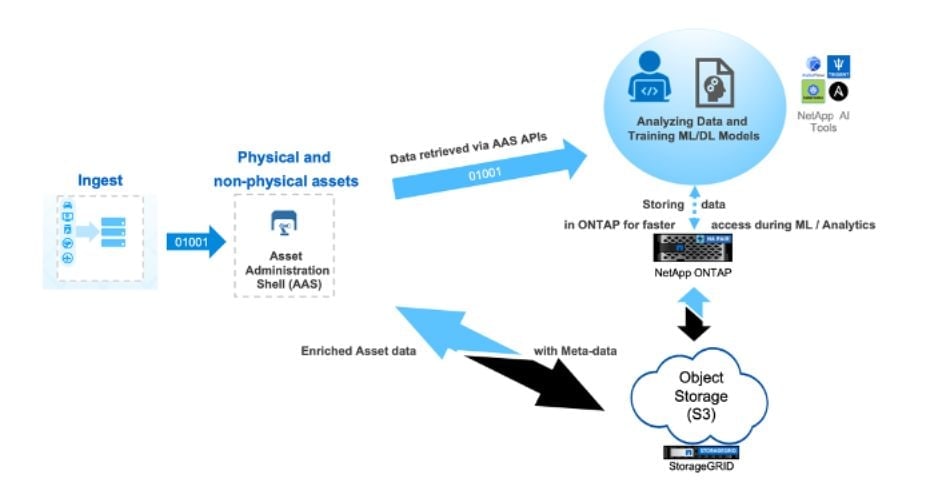
Now that we've described the approach of setting up an Industry 4.0 stack, what about using the captured information to drive valuable insights? You can directly use the data stored as objects via AAS to perform analysis. And you can use machine learning and deep learning to automate the process, optimize supply chain management, perform predictive maintenance, and more. If you need to perform training and analysis at scale, you might want to leverage fast storage. The NetApp DataOps Toolkit is a Python library that allows you to move data from object storage to high-performance, scale-out NetApp storage. From there you could leverage GPUs and other computational resources to carry out the analysis, ML model training, and deployment in a production environment. The toolkit enables developers, data scientists, DevOps engineers, and data engineers to manage data quickly and easily. It also makes it possible to perform various data management tasks, such as creating a new data volume, quickly cloning an existing dataset, and near-instantaneously creating versions of data and associated trained model for tracking and reproducibility.
Try it yourself!
If this blog post has piqued your interest, check out the solution and give it a try. You can find the setup and code used for this solution at GitHub.
Muneer Ahmad Dedmari
Next Steps
.png?width=5760&format=avif&disable=upscale)