Zone di disponibilità, regioni e gruppi di posizionamento AWS spiegati
Condivi questa pagina

Aviv Degani
Le organizzazioni aziendali utilizzano applicazioni che richiedono diversi livelli di disponibilità e diversi obiettivi SLA. Quanto un'applicazione sia critica o esigente è proporzionale ai suoi requisiti di throughput, reattività e tempi di ripristino in caso di guasto. Le stesse considerazioni valgono quando si definiscono le best practice di AWS per l'alta disponibilità.
A seconda dei requisiti specifici della distribuzione, distribuire elaborazione e storage tra le AWS Availability Zones in combinazione con i Placement Groups è un modo per affrontare questa sfida nell'alta disponibilità AWS. Una combinazione ottimizzata di queste opzioni, insieme a una distribuzione Cloud Volumes ONTAP HA, può soddisfare i requisiti presentati da ciascun layer.
In questo articolo esamineremo queste best practice per l'alta disponibilità AWS e i casi d'uso per Availability Zone singole e multiple, e Placement Groups. Vedremo anche i vantaggi aggiuntivi che Cloud Volumes ONTAP HA può offrire come soluzione a livello di storage.
In questo articolo scoprirai:
- Cosa sono AWS Regions e Availability Zones?
- Parametri da considerare nella scelta di una AWS Region
- Cos'è una Multi-AZ Deployment?
- AWS Placement Groups
- Cloud Volumes ONTAP HA per AWS
Cosa sono AWS Regions e Availability Zones?
Le Availability Zones sono data center ad alta disponibilità all'interno di ciascuna AWS Region. Una region rappresenta un'area geografica separata. Ogni Availability Zone ha alimentazione, raffreddamento e rete indipendenti. Quando un'intera Availability Zone si interrompe, AWS è in grado di eseguire il failover dei carichi di lavoro su una delle altre zone nella stessa region, una funzionalità nota come “Multi-AZ” ridondanza.
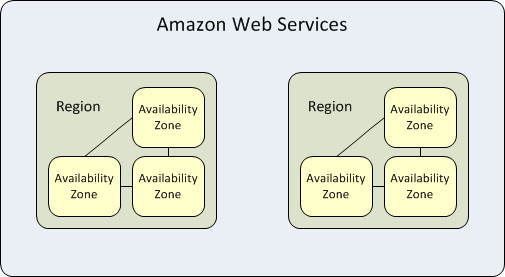
Ogni AWS Region è isolata e opera indipendentemente dalle altre region ma le Availability Zones all'interno di ciascuna region sono collegate tramite collegamenti a bassa latenza per fornire replica e tolleranza ai guasti. Se ospiti tutti i tuoi dati e istanze in una sola Availability Zone, che viene colpita da un guasto, non sarebbero disponibili.
Lo scopo di questo isolamento è servire carichi di lavoro con elevati requisiti di sovranità dei dati e conformità che non permettono ai dati degli utenti di uscire da una specifica area geografica. Questi tipi di carichi di lavoro beneficiano della struttura delle Availability Zones AWS con bassa latenza e completa separazione dalle altre region.
Consulta un elenco completo delle region disponibili nell'infrastruttura globale AWS.
AWS Regions vs. Availability Zones
Ci sono due differenze operative chiave tra l'esecuzione dei carichi di lavoro in region diverse rispetto a diverse Availability Zones all'interno della stessa region.
Distribuzione geografica
La distribuzione geografica delle AWS Regions e Availability Zones gioca anche un ruolo significativo nelle prestazioni e nell'affidabilità delle applicazioni.
Se distribuisci la tua applicazione su più Availability Zones in una sola region, puoi ottenere un certo livello di alta disponibilità e tolleranza ai guasti, ma inferiore rispetto a una distribuzione in region diverse. Se una Availability Zone fallisce, la tua applicazione può continuare a funzionare in un'altra Availability Zone senza interruzioni. Tuttavia, se l'intera region fallisce, la tua applicazione fallirà.
D'altra parte, distribuire la tua applicazione in più region significa che anche se un'intera region fallisce (scenario molto improbabile), la tua applicazione può continuare a funzionare. La distribuzione tra region offre benefici aggiuntivi come riduzione della latenza per gli utenti globali e disaster recovery più rapido.
Costi di elaborazione e trasferimento dati
Quando si tratta di costi, la posizione delle risorse AWS può avere un impatto significativo. Ogni AWS Region ha prezzi diversi per i servizi a causa di fattori come domanda locale, costi infrastrutturali e leggi fiscali locali. Ad esempio, eseguire una istanza EC2 nella region Asia Pacific (Mumbai) probabilmente costerà di più rispetto alla stessa istanza nella region US East (N. Virginia). Tuttavia, il costo di esecuzione dei carichi di lavoro su diverse AZ nella stessa region è generalmente lo stesso.
Inoltre, i costi di trasferimento dati possono variare a seconda che i dati vengano trasferiti all'interno della stessa region, tra region diverse o tra region e internet pubblico. Trasferire dati all'interno della stessa region o tra Availability Zones nella stessa region è generalmente più economico rispetto al trasferimento tra region o verso internet pubblico.
Parametri da considerare nella scelta di una AWS Region
Alcuni parametri sono fondamentali da considerare prima di scegliere una AWS Region e AZ per ospitare e distribuire la tua applicazione per ottenere i migliori risultati.
L'elenco seguente fornisce i parametri più importanti da prendere in considerazione:
Parametro #1: Latenza e prossimità—scegli la region più vicina per bassa latenza.
Una connessione veloce al server garantisce migliori prestazioni in termini di tempi di caricamento e trasferimento rapidi, con conseguente migliore esperienza utente. Puoi ottenere questo scegliendo una AWS Region più vicina alla maggioranza della base clienti. Minore è la distanza tra il cloud e l'utente finale, minore è la latenza. Ad esempio, se la maggior parte dei tuoi clienti accede alla tua applicazione nella region Nord America, scegliere una Availability Zone all'interno delle region USA o Canada darà i migliori risultati.
I prezzi dei servizi AWS variano a seconda della region in base a elementi come il costo dell'infrastruttura fisica e le tasse. La differenza tra le varie region può ammontare a centinaia di dollari, quindi scegliere quella giusta è fondamentale per ridurre costi inutili. Puoi usare il calcolatore prezzi ufficiale per vedere quale region si adatta meglio alle tue esigenze. Consulta anche il NetApp AWS Calculator, che ti permette di calcolare il TCO incluso il costo dei servizi di storage.
Parametro #2: Costo—scegli una region che offra il miglior rapporto prezzo-prestazioni.
Di seguito una tabella di riferimento che mostra i vari prezzi per ciascuna region per un trasferimento dati di 1TB.
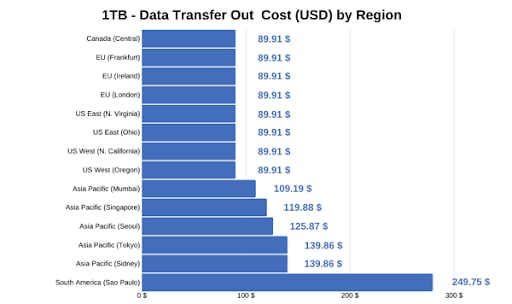
Parametro #3: Conformità normativa e sicurezza—protezione degli asset aziendali
Ogni paese o unione ha un diverso insieme di norme e regole di conformità per proteggere i dati degli utenti. Alcune region potrebbero vietare il trasferimento tra la propria region e altre region. La violazione di tali normative di conformità può portare a cause legali e causare danni finanziari e reputazionali critici alla tua organizzazione. Inoltre, se offri servizi a livello globale, dovresti considerare l'utilizzo di più AWS Region e Availability Zones per offrire il servizio più veloce e affidabile ai tuoi clienti.
Parametro #4: Service Level Agreements (SLA)—parametri giusti per ottenere un servizio migliore.
I servizi AWS offrono diversi SLA in base alla loro disponibilità e parametri specifici. AWS rispetterà meglio gli SLA quando distribuisci l'applicazione secondo la progettazione AWS. Considera tutti gli altri parametri insieme ai tuoi requisiti quando selezioni una region e una AZ per assicurarti che offrano la soluzione migliore per ospitare e distribuire la tua applicazione.
Cos'è una Multi-AZ Deployment?
Quando si tratta di carichi di lavoro mission critical, come enterprise database— sia ospitati su Amazon EC2 instances che su servizi database nativi Amazon (come Amazon RDS)—un modello di distribuzione multi-AZ offre alta disponibilità in caso di guasto grave in un'intera Availability Zone.
Le applicazioni di produzione critiche che non possono permettersi nemmeno un moderato downtime beneficiano di questo modello e devono considerare questo tipo di guasto generale come una reale possibilità. Lo stesso vale per i livelli superiori di cui questa applicazione può essere composta. Se i servizi web di un'app sono tutti ospitati in una sola AZ, avere i database sottostanti in una configurazione HA multi-AZ non aiuterà molto se il tier web è ospitato in una sola AZ.
Da questa prospettiva di alta disponibilità, in una distribuzione single AZ, se la AZ va giù tutto va giù e il Recovery Time Objective aumenta notevolmente. Senza contare la perdita di dati che si verificherà nel frattempo.
Altri importanti vantaggi delle distribuzioni multi-AZ includono:
- Nessun ritardo di I/O durante i backup, poiché i backup vengono eseguiti dall'istanza di standby.
- Nessuna interruzione di I/O durante l'applicazione di patch o l'esecuzione di upgrade per scopi di manutenzione.
- Aumento della reattività quando si utilizza il load balancing. Se una AZ è congestionata, le istanze nelle altre zone possono gestire il traffico.
Ovviamente, non tutti i casi d'uso applicativi richiedono una distribuzione multi-AZ. Test temporanei, distribuzioni di sviluppo o qualsiasi caso d'uso non critico possono essere ospitati in una sola AZ ed evitare i costi aggiuntivi di una multi-AZ. Esistono anche casi d'uso ad alta intensità e a bassa latenza che si adattano meglio al modello single-AZ.
AWS Placement Groups
In parole semplici, un Placement Group è un'opzione di configurazione che AWS offre e che consente di posizionare un gruppo di istanze interdipendenti in un certo modo sull'hardware sottostante su cui risiedono tali istanze. Le istanze possono essere posizionate vicine tra loro, distribuite su rack diversi o distribuite su diverse Availability Zones. Vediamo più da vicino ciascuno dei tipi di Placement Group che puoi scegliere e i tipi di carichi di lavoro che meglio si adattano a ciascuna opzione di distribuzione:
1. Cluster Placement Groups
La configurazione cluster placement group consente di posizionare il gruppo di istanze interrelate vicine tra loro per ottenere il miglior throughput e risultati di bassa latenza possibili. Questa opzione consente di raggruppare le istanze solo all'interno della stessa Availability Zone, nella stessa VPC o tra VPC peered.
Il vantaggio dei cluster placement group è che la comunicazione tra queste istanze non è limitata a traffico single-flow di 5 Gbps ma a traffico single-flow (point-to-point) di 10 Gbps e un totale di 25 Gbps per traffico aggregato. Le applicazioni HPC (High Performance Computing) network-bound sono i migliori casi d'uso per questo modello di distribuzione. Ingegneria computazionale, streaming di eventi live, sequenziamento genomico, modelli astronomici e modelli di calcolo climatico terrestre sono esempi di casi d'uso per questo tipo di raggruppamento nel cloud.
2. Partition Placement Groups
Con i partition placement group puoi raggruppare le istanze in partizioni logiche separate che formano il placement group. L'idea è che ciascuna delle partizioni logiche sia costruita su rack hardware separati per evitare guasti hardware comuni. Se un rack fallisce, interesserà solo le istanze che risiedono su questa partizione logica. Ogni partizione logica è composta da più istanze. L'opzione partition placement group consente di posizionare queste partizioni all'interno di una sola AZ o in una configurazione multi-AZ nella stessa region.
Quindi, che tipo di carichi si adattano meglio a questo modello? Big data store che devono essere distribuiti e replicati sono buoni esempi. Anche grandi file system come HDFS o Cassandra sono ottimi esempi. I partition placement group ti permettono di vedere quali istanze sono posizionate in quali partizioni così puoi rendere Hadoop o Cassandra topology-aware e configurare la replica dei dati correttamente. Qualsiasi caso d'uso che richieda big data analysis, data reporting o indicizzazione su larga scala sarebbe adatto ai partition placement group.
3. Spread Placement Groups
Con gli spread placement group, ogni singola istanza gira su rack hardware fisici separati. Quindi, se distribuisci cinque istanze e le inserisci in questo tipo di placement group, ognuna di queste cinque istanze risiederà su un rack diverso con la propria rete e alimentazione, sia in una sola AZ che in architettura multi-AZ.
La configurazione spread placement group può essere simile ai partition placement group, ma la differenza principale è che i partition placement group sono composti da più istanze su ogni partizione, mentre gli spread group sono singole istanze individuali distribuite su rack o AZ diversi.
Questo modello è raccomandato per un piccolo numero di istanze critiche per il tuo business. Potresti avere una piccola quantità di SQL database istanze in esecuzione qui o il tuo tier applicativo web. Questa configurazione è un caso d'uso ideale per la ridondanza, poiché c'è meno necessità della potenza computazionale offerta da partition e cluster placement group.
Cloud Volumes ONTAP HA per AWS
La Cloud Volumes ONTAP HA configuration fornisce AWS high availability. Eseguendo su due nodi di Amazon EC2 compute instances e archiviando tutti i dati nel sottostante Amazon EBS storage, le operazioni possono prevenire qualsiasi perdita di dati in caso di guasto e recuperare in meno di 60 secondi.
In questa coppia Cloud Volumes ONTAP, tutti i dati sono replicati tra i due nodi, sia in configurazione active-active, dove entrambi i nodi servono i client, sia in configurazione active-passive, in cui un nodo è in standby. In entrambi i casi i dati sono replicati in modo sincrono ogni volta che vengono scritti nuovi dati. Questa configurazione può essere implementata sia in uno scenario single AZ che multi-AZ:
- Single-AZ: entrambi i nodi Cloud Volumes ONTAP risiedono nella stessa Availability Zone. NetApp Cloud Manager distribuisce automaticamente entrambi i nodi con una configurazione spread placement group per evitare guasti comuni di calcolo.
- Multi-AZ: ogni nodo Cloud Volumes ONTAP risiede in una Availability Zone diversa, eliminando nuovamente la AZ come single point of failure, cosa che non è una caratteristica offerta dalla replica storage nativa Amazon EBS. Con questa configurazione di alta disponibilità è necessario configurare un AWS Transit Gateway con indirizzi IP flottanti affinché il failover funzioni correttamente e fornisca accesso NAS permanente o accesso ai dati.
Cloud Volumes ONTAP HA richiede tre Amazon EC2 instances per funzionare: due nodi principali che gestiscono tutto lo storage e una piccola istanza mediatrice t2.micro incaricata di regolare e amministrare le attività automatiche di failover e failback. RPO (Recovery Point Objective) è zero, i tuoi dati sono sempre consistenti poiché sono replicati in modo sincrono, e il tuo RTO (Recovery Time Objective) è di 60 secondi o meno per rendere nuovamente disponibili i dati in caso di failover sull'altro nodo.
AWS ha altre funzionalità native di ridondanza a livello storage come Amazon EBS. Come già detto, Amazon EBS replica solo all'interno dei server su una sola Availability Zone e se vuoi fornire ridondanza a livello storage usando solo Amazon EBS, dovresti fare snapshot Amazon S3 e trasferirli su una Availability Zone diversa, con costi aggiuntivi. Altre funzionalità native AWS di alta disponibilità a livello storage come Amazon EFS esportano i dati solo tramite NFS e attualmente non supportano le istanze Windows.
Conclusione
Tutte le informazioni fornite in questo articolo sulle best practice AWS per l'alta disponibilità portano a tre principali conclusioni:
- Ovunque sia presente una configurazione multi-AZ, si ottiene un punto di affidabilità aggiuntivo poiché l'intera Availability Zone viene esclusa come single point of failure.
- Carichi di lavoro diversi hanno diversi set di requisiti che possono adattarsi meglio a deployment single-AZ o multi-AZ.
- Ogni volta che è necessario uno storage centralizzato, Cloud Volumes ONTAP HA è una soluzione che offre ridondanza e recupero rapido a livello storage, sia che tu stia distribuendo in modalità single-AZ che multi-AZ. Questo a un prezzo inferiore o comparabile rispetto all'esecuzione su raw Amazon EBS storage.
La business continuity è importante. Cloud Volumes ONTAP ti dà la possibilità di garantirla.